S03-08 JS-高级-函数增强
[TOC]
闭包@
闭包-概念
又爱又恨的闭包
闭包是 JavaScript 中一个非常容易让人迷惑的知识点:
有同学在深入 JS 高级的交流群中发了这么一张图片;
并且闭包也是群里面大家讨论最多的一个话题;

闭包确实是 JavaScript 中一个很难理解的知识点,接下来我们就对其一步步来进行剖析,看看它到底有什么神奇之处。
JS的函数式编程
在前面我们说过,JavaScript 是支持函数式编程的
在 JavaScript 中,函数是非常重要的,并且是一等公民:
那么就意味着函数的使用是非常灵活的;
函数可以作为另外一个函数的参数,也可以作为另外一个函数的返回值来使用;
所以 JavaScript 存在很多的高阶函数:
自己编写高阶函数
使用内置的高阶函数
目前在 vue3 和 react 开发中,也都在趋向于函数式编程:
vue3 composition api: setup 函数 -> 代码(函数 hook,定义函数);
react:class -> function -> hooks
闭包的定义
这里先来看一下闭包的定义,分成两个:在计算机科学中和在 JavaScript 中。
维基百科定义:在计算机科学中对闭包的定义(维基百科):
闭包(Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures);
是在支持头等函数的编程语言中,实现词法绑定的一种技术;
闭包在实现上是一个结构体,它存储了一个函数和一个关联的环境(相当于一个符号查找表);
闭包跟函数最大的区别在于,当捕捉闭包的时候,它的自由变量会在捕捉时被确定,这样即使脱离了捕捉时的上下文,它也能照常运行;
历史:闭包的概念出现于 60 年代,最早实现闭包的程序是 Scheme,那么我们就可以理解为什么 JavaScript 中有闭包:
- 因为 JavaScript 中有大量的设计是来源于 Scheme 的;
MDN定义:我们再来看一下MDN对 JavaScript 闭包的解释:
一个函数和对其周围状态(lexical environment,词法环境)的引用捆绑在一起(或者说函数被引用包围),这样的组合就是闭包(closure);
也就是说,闭包让你可以在一个内层函数中访问到其外层函数的作用域;
在 JavaScript 中,每当创建一个函数,闭包就会在函数创建的同时被创建出来;
DeepSeek:
闭包(Closure) 是指一个函数能够记住并访问其所在的词法作用域(Lexical Scope),即使该函数在其词法作用域之外执行。简单来说,闭包允许函数访问其定义时所在的作用域中的变量,即使该作用域已经销毁。闭包的本质是函数与其词法作用域的结合。
自己总结:那么我的理解和总结:
一个普通的函数function,如果它可以访问外层作用域的自由变量**,那么这个函数和周围环境就是一个**闭包****;
从广义的角度来说:JavaScript 中的函数都是闭包;
从狭义的角度来说:JavaScript 中一个函数,如果访问了外层作用域的变量,那么它是一个闭包;
闭包-形成过程
闭包的访问过程
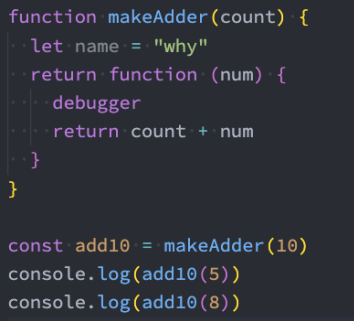
如果我们编写了如下的代码,它一定是形成了闭包的:
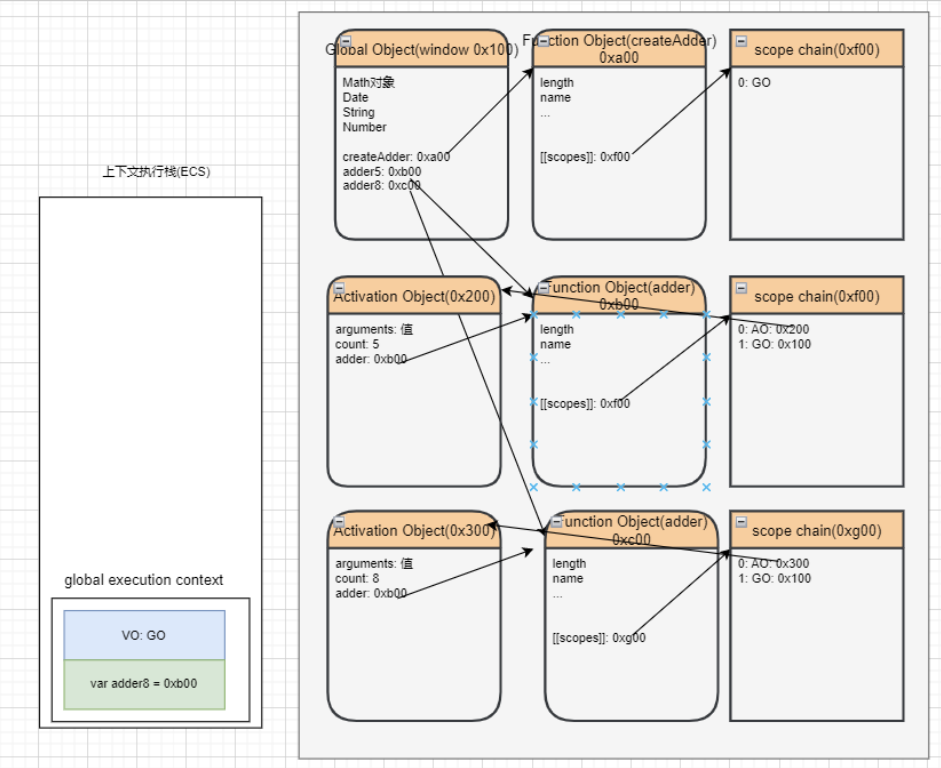
闭包的执行过程
那么函数继续执行呢?
这个时候 makeAdder 函数执行完毕,正常情况下我们的 AO 对象会被释放;
但是因为在 0xb00 的函数中有作用域引用指向了这个 AO 对象,所以它不会被释放掉;
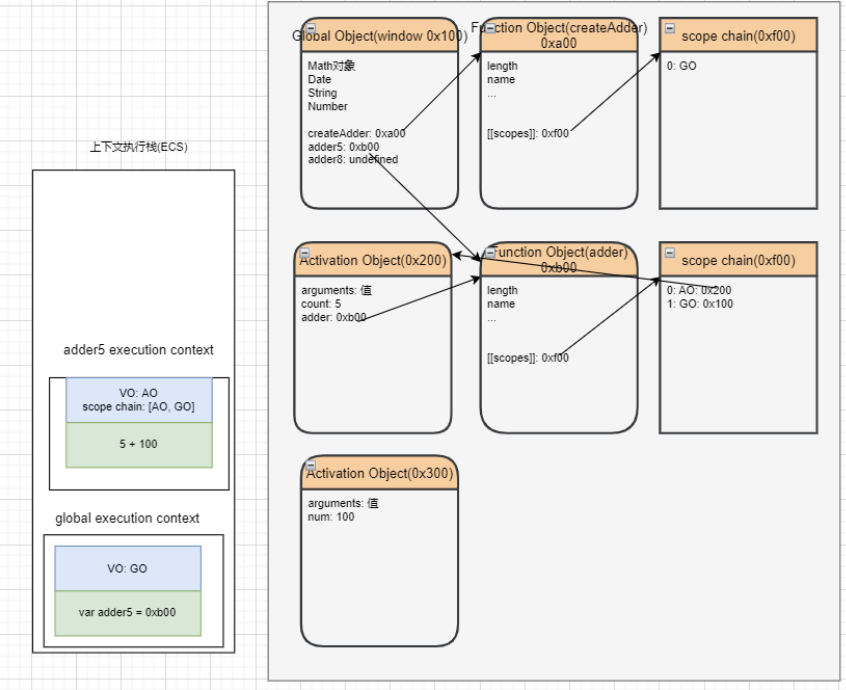
闭包-内存泄露
闭包的内存泄漏
那么我们为什么经常会说闭包是有内存泄露的呢?
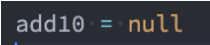
在上面的案例中,如果后续我们不再使用 add10 函数了,那么该函数对象应该要被销毁掉,并且其引用着的父作用域 AO 也应该被销毁掉;
但是目前因为在全局作用域下 add10 变量对 0xb00 的函数对象有引用,而 0xb00 的作用域中 AO(0x200)有引用,所以最终会造成这些内存都是无法被释放的;
所以我们经常说的闭包会造成内存泄露,其实就是刚才的引用链中的所有对象都是无法释放的;
那么,怎么解决这个问题呢?
因为当手动将 add10 设置为 null时,就不再对函数对象 0xb00 有引用,那么对应的 AO 对象 0x200 也就不可达了;
在 GC 的下一次检测中,它们就会被销毁掉;
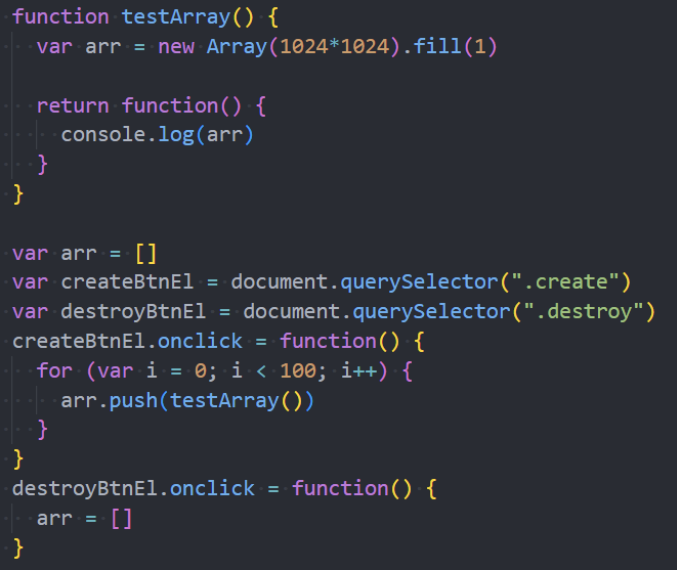
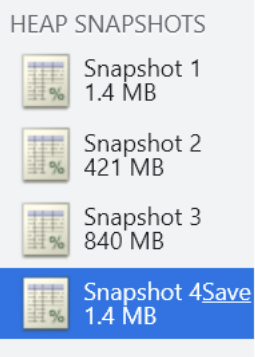
闭包的内存泄漏测试
AO不使用的属性优化
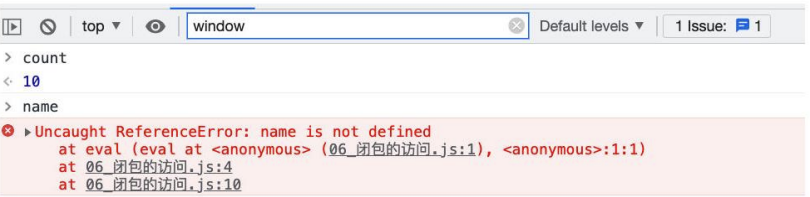
我们来研究一个问题:AO 对象不会被销毁时,是否里面的所有属性都不会被释放?
下面这段代码中 name 属于闭包的父作用域里面的变量;
我们知道形成闭包之后 count 一定不会被销毁掉,那么 name 是否会被销毁掉呢?
这里我打上了断点,我们可以在浏览器上看看结果;
函数增强
API-Function
属性:
- function.name:
string,只读,返回函数定义时的名称,推断规则因定义方式而异。适用于调试、反射(获取函数名)等场景。 - function.length:
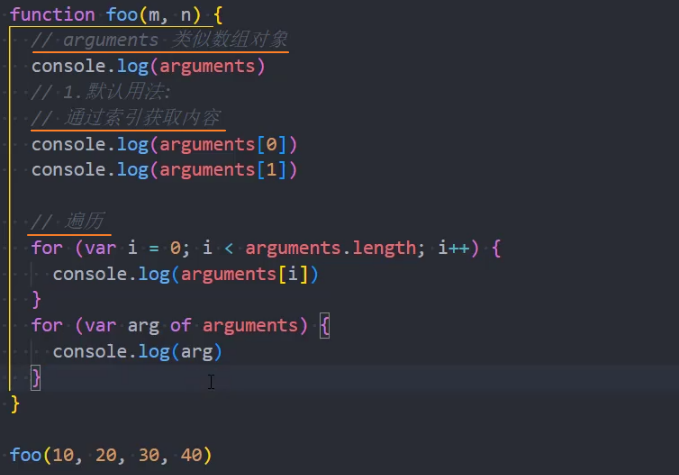
number,表示函数声明时定义的形参数量。它不会将默认参数之后的参数、剩余参数计算在内。 - function.arguments:
类数组对象,已废弃,用于在函数内部访问函数执行时传入的参数列表,它是一个类数组对象。 - function.prototype:
object,是所有函数对象的原型对象。它定义了函数实例继承的默认属性和方法。
方法:
- function.call():
(thisArg,arg1?,arg2?,...),用于显式调用一个函数,并动态指定函数执行时的 this 值及参数列表。 - function.apply():
(thisArg,args?),用于显式调用一个函数,并动态指定函数执行时的 this 值及参数列表。 - function.bind():
(thisArg,arg1?,arg2?,...),用于创建一个新的函数,该函数在调用时会以指定的 this 值和预先提供的参数作为默认参数。 - function.toString():
(),用于获取函数源代码字符串表示的方法。它返回函数的完整定义,包括参数、函数体和语法结构。
类数组对象
概述
类数组对象(Array-like Object):是 JavaScript 中一种特殊的对象类型,它具有类似数组的结构(数字索引和 length 属性),但不具备数组的原生方法(如 push、pop、forEach 等)。这类对象在 JavaScript 中非常常见,通常出现在与 DOM 操作、函数参数处理等场景中。
类数组对象的特征:
- 数字索引属性:可以通过
[0]、[1]等数字索引访问元素。 length属性:表示元素的个数,与数组的length行为一致。- 不具备数组方法:无法直接调用
push()、slice()等数组方法。
常见的类数组对象:
- argumets 对象:函数内部通过 arguments 访问传入的参数列表。
- DOM 集合:
HTMLCollection:由 document.getElementsByTagName() 返回。NodeList:由 document.querySelectorAll() 返回。
- 字符串:字符串本质上是类数组对象,每个字符对应一个数字索引。
转数组类型方法
转数组类型方法:由于类数组对象无法直接使用数组方法,通常需先将其转换为真正的数组。
方法1:
Array.from()jsconst args = Array.from(arguments); args.push(3); // 现在可以使用数组方法方法2:扩展运算符(
...)jsconst nodeList = document.querySelectorAll('div'); const divArray = [...nodeList]; // 转为数组 divArray.forEach(div => console.log(div));方法3:
Array.prototype.slice.call()jsfunction sum() { const args = Array.prototype.slice.call(arguments); args.push(3); // 现在可用数组方法 }
判断类数组对象
判断类数组对象:
原理:检查对象是否满足以下条件:
- 是对象:
typeof obj === 'object'且不为null - 有 length 属性:
obj.length >= 0 - 有数字索引属性:如
obj[0]存在
实现代码:
function isArrayLike(obj) {
if (obj == null || typeof obj !== 'object') return false;
const length = obj.length;
return typeof length === 'number' &&
length >= 0 &&
(length === 0 || (length > 0 && (length - 1) in obj));
}剩余参数
剩余参数(Rest Parameters):是 ES6 引入的一种语法特性,允许函数接收不定数量的参数,并将这些参数自动转换为一个数组。它通过 ... 符号定义,使得处理可变参数更加简洁和灵活。
语法特性:
语法定义:使用
...参数名作为函数的最后一个形参,收集剩余的所有参数:jsfunction sum(...numbers) { return numbers.reduce((total, num) => total + num, 0); } console.log(sum(1, 2, 3)); // 6必须是最后一个参数:剩余参数只能位于参数列表的末尾,甚至要在默认参数之后,否则会报错:
js// 正确 function invalid(a, b, ...rest) {} // OK function invalid(a, b = 0, ...rest) {} // OK // 错误示例 function invalid(a, ...rest, b) {} // SyntaxError function invalid(a, ...rest, b = 0) {} // SyntaxError与普通参数共存:可与其他参数结合使用,剩余参数收集“剩下的”参数:
jsfunction greet(greeting, ...names) { console.log(`${greeting}, ${names.join(', ')}!`); } greet("Hello", "Alice", "Bob"); // "Hello, Alice, Bob!"只能使用一次:一个函数中只能有一个剩余参数:
jsfunction invalid(a, ...rest1, ...rest2) {} // 错误与箭头函数配合:箭头函数没有
arguments,剩余参数是唯一选择:jsconst add = (...nums) => nums.reduce((a, b) => a + b); console.log(add(1, 2, 3)); // 6
对比 arguments:
| 特性 | 剩余参数 | arguments 对象 |
|---|---|---|
| 类型 | 真正的数组 | 类数组对象(需转换才能用数组方法) |
| 箭头函数中可用 | ✅ 是 | ❌ 箭头函数无 arguments |
| 可读性与灵活性 | 直接命名,语义清晰 | 无命名,需通过索引访问 |
| 与其他参数共存 | 可结合普通参数和解构赋值 | 只能通过索引访问所有参数 |
| 包含参数 | 只包含没有对应形参的实参(剩余的参数) | 包含所有实参 |
应用场景:
处理不定数量的参数
jsfunction logMessages(...messages) { messages.forEach(msg => console.log(msg)); } logMessages("Error", "Warning", "Info"); // 逐行输出与解构赋值结合
数组解构:收集剩余元素
jsconst [first, ...others] = [1, 2, 3, 4]; console.log(first); // 1 console.log(others); // [2, 3, 4]对象解构:收集剩余属性
jsconst { x, y, ...rest } = { x: 1, y: 2, z: 3, a: 4 }; console.log(rest); // { z: 3, a: 4 }
替代
arguments对象js// 旧方式(arguments) function oldSum() { const args = Array.from(arguments); return args.reduce((a, b) => a + b, 0); } // 新方式(剩余参数) function newSum(...args) { return args.reduce((a, b) => a + b, 0); }
函数对象属性
我们知道 JS 中函数也是一个对象,那么对象中就可以有属性和方法。
函数对象的属性可以分为:
- 自定义函数属性
- 内置函数属性
自定义函数属性
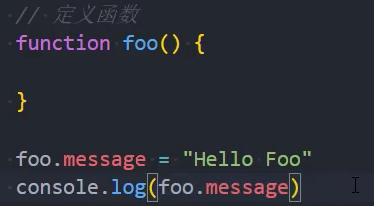
内置函数属性
function.name:
string,只读,返回函数定义时的名称,推断规则因定义方式而异。适用于调试、反射(获取函数名)等场景。function.length:
number,表示函数声明时定义的形参数量。它不会将默认参数之后的参数、剩余参数计算在内。function.arguments:
类数组对象,已废弃,用于在函数内部访问函数执行时传入的参数列表,它是一个类数组对象。
示例:
纯函数
纯函数
函数式编程中有一个非常重要的概念叫纯函数(Pure Function),JavaScript 符合函数式编程的范式,所以也有纯函数的概念;
在react开发中纯函数是被多次提及的;
比如react 中组件就被要求像是一个纯函数(为什么是像,因为还有 class 组件),redux 中有一个 reducer 的概念,也是要求必须是一个纯函数;
所以掌握纯函数对于理解很多框架的设计是非常有帮助的;
维基百科:纯函数的维基百科定义:
在程序设计中,若一个函数符合以下条件,那么这个函数被称为纯函数:
此函数在相同的输入值时,需产生相同的输出。
函数的输出和输入值以外的其他隐藏信息或状态无关,也和由 I/O 设备产生的外部输出无关。
该函数不能有语义上可观察的函数副作用,诸如“触发事件”,使输出设备输出,或更改输出值以外物件的内容等。
纯函数(Pure Function):是函数式编程中的核心概念,它指满足以下两个条件的函数:
- 相同输入,相同输出:在给定相同的参数时,总是返回相同的结果,不受外部状态或环境变化的影响。
- 无副作用(No Side Effects):函数执行过程中不会修改任何外部状态,包括:
- 不修改全局变量、外部对象或传入的参数。
- 不执行 I/O 操作(如读写文件、网络请求、DOM 操作等)。
- 不触发外部事件(如日志输出、计时器等)。
副作用
那么这里又有一个概念,叫做副作用,什么又是副作用呢?
副作用(side effect):
其实本身是医学的一个概念,比如我们经常说吃什么药本来是为了治病,可能会产生一些其他的副作用;
在计算机科学中,也引用了副作用的概念,表示在执行一个函数时,除了返回函数值之外,还对调用函数产生了附加的影响,比如修改了全局变量,修改参数或者改变外部的存储;
纯函数在执行的过程中就是不能产生这样的副作用:
- 副作用往往是产生 bug 的 “温床”。
示例:副作用:修改了参数、外部变量
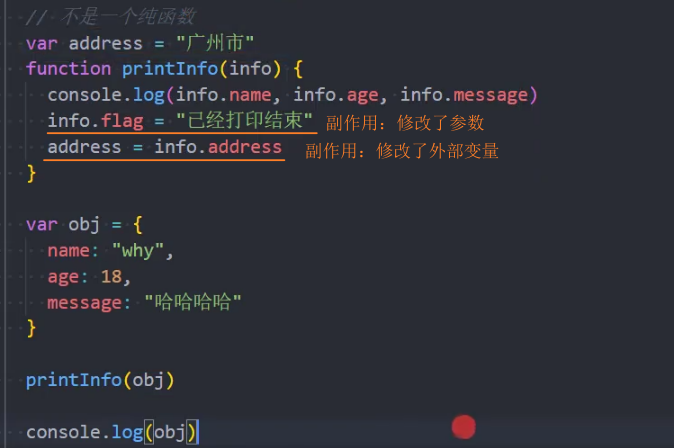
练习:判断纯函数
1、是纯函数
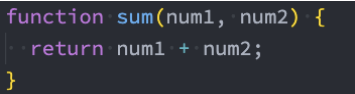
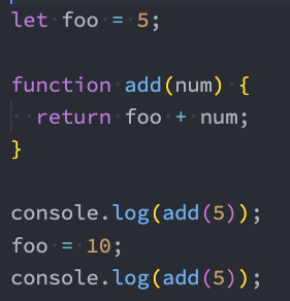
2、不是纯函数:访问了外部变量 foo
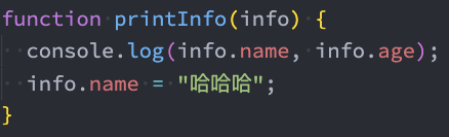
3、不是纯函数:修改了外部对象 info.name
数组中的纯函数
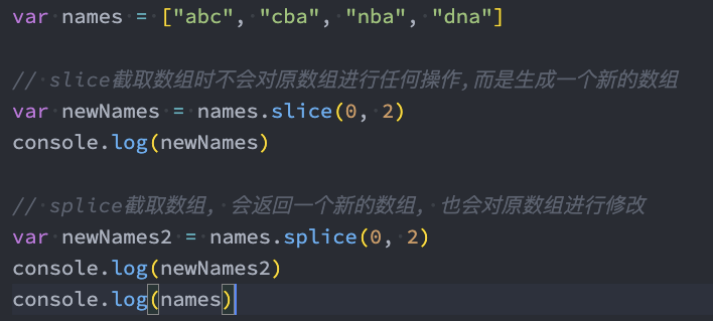
数组中的纯函数:我们来看一个对数组操作的两个函数:
- array.slice:
(start?,end?),取值:[start,end),纯函数,用于提取数组的一部分,返回新数组。 - array.splice():
(start,deleteCount?,item1?,item2?,...),修改原数组,可以删除、替换或添加元素。返回被删除的元素组成的数组。
作用和优势
为什么纯函数在函数式编程中非常重要呢?
作用:
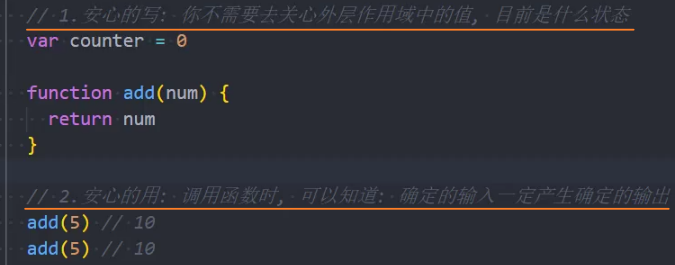
安心的编写和安心的使用
安心的编写:写的时候保证了函数的纯度,只是单纯实现自己的业务逻辑即可,不需要关心传入的内容是如何获得的或者依赖其他的外部变量是否已经发生了修改。
安心的使用:用的时候可以确定输入内容不会被任意篡改,并且确定的输入,一定会有确定的输出。
react 要求组件是一个纯函数
React中要求我们无论是函数还是 class 声明一个组件,这个组件都必须像纯函数一样,保护它们的 props 不被修改

编写纯函数
如何编写纯函数:
避免依赖外部变量
所有数据通过参数传递,而非直接使用全局变量。
js// 不纯(依赖外部变量) const TAX_RATE = 0.1; function calculateTax(price) { return price * TAX_RATE; } // 纯(依赖参数) function calculateTaxPure(price, taxRate) { return price * taxRate; }不修改输入参数
对对象或数组的操作应返回新值,而非直接修改原数据。
js// 不纯(修改输入) function addToCartImpure(cart, item) { cart.push(item); return cart; } // 纯(返回新数组) function addToCartPure(cart, item) { return [...cart, item]; }隔离副作用
将 I/O 操作、状态修改等副作用与纯逻辑分离,如通过高阶函数包装。
js// 副作用隔离:纯函数处理逻辑,非纯函数处理 I/O function logResult(impureAction) { return (...args) => { const result = impureAction(...args); console.log("Result:", result); return result; }; } const pureAdd = (a, b) => a + b; const loggedAdd = logResult(pureAdd);
柯里化
概述
柯里化(Currying):是一种函数式编程技术,将一个接受多个参数的函数转换为一系列嵌套的单参数函数。每次调用接收一个参数并返回一个新函数,直到所有参数被收集完毕,最终返回计算结果。柯里化的核心目的是增强函数的复用性和灵活性,支持部分参数应用(Partial Application)。
核心概念:
- 函数转换:将多参数函数转化为单参数函数的链式调用。如,
add(a, b, c)柯里化为add(a)(b)(c)。 - 延迟执行:分步传递参数,按需触发最终计算。
- 部分应用:提前固定部分参数,生成更具体的函数。
柯里化(Currying)也是属于函数式编程里面一个非常重要的概念。
是一种关于函数的高阶技术;
它不仅被用于 JavaScript,还被用于其他编程语言;
维基百科:
柯里化(Currying,卡瑞化,加里化):是把接收多个参数的函数,变成接收一个单一参数(最初函数的第一个参数)的函数,并返回接收余下的参数且返回结果的新函数的技术;
- 柯里化声称 “如果你固定某些参数,你将得到接受余下参数的一个函数”;
总结:维基百科的解释非常的抽象,我们这里做一个总结:
- 只传递给函数一部分参数来调用它,让它返回一个函数去处理剩余的参数,这个过程就称之为柯里化;
柯里化是一种函数的转换,将一个函数从可调用的 f(a, b, c) 转换为可调用的 f(a)(b)(c)。
- 柯里化不会调用函数。它只是对函数进行转换。
柯里化函数
柯里化函数:
那么柯里化到底是怎么样的表现呢?
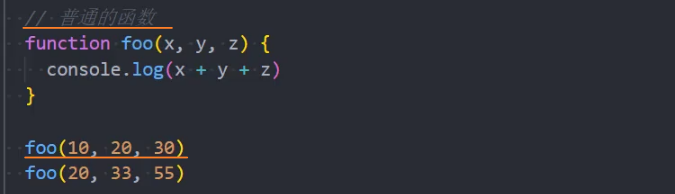
1、普通的函数
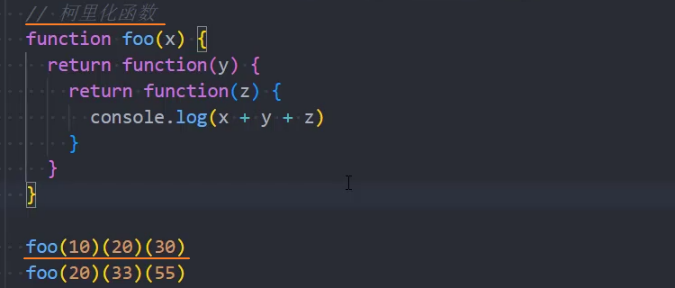
2、柯里化函数
3、柯里化函数(箭头函数写法)

示例:
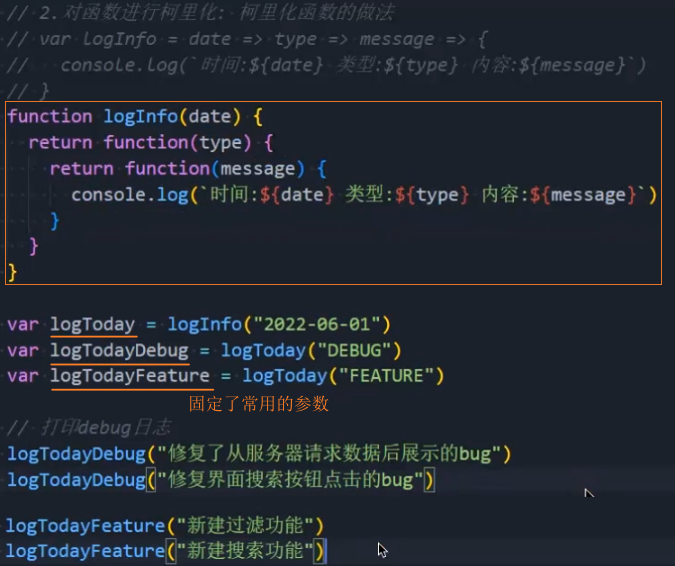
打印日志
1、普通函数实现
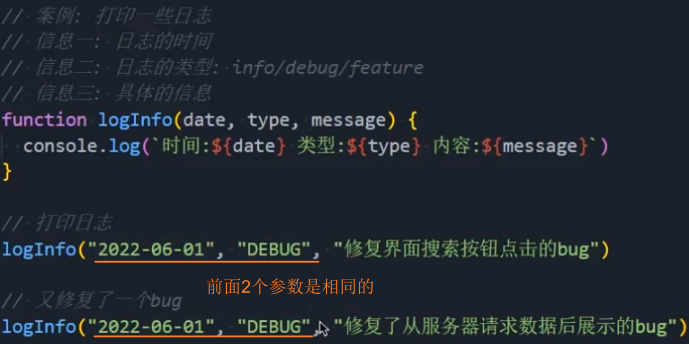
2、柯里化函数实现:可以发现普通函数打印日志时,前面2个参数是相同的,可以通过柯里化函数优化
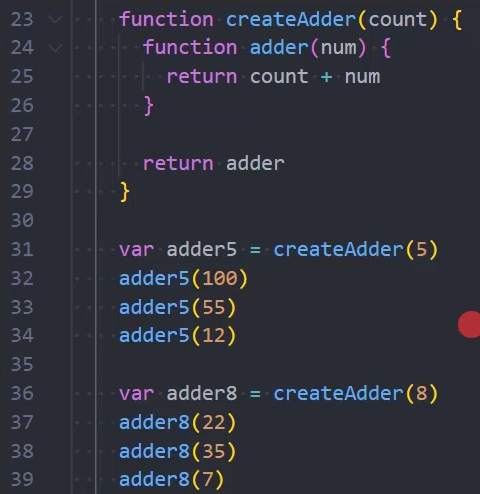
工厂函数 makeAdder
柯里化的优势
柯里化的优势:
- 职责单一:一个函数处理的问题尽可能的单一。
- 参数复用:提前固定部分参数,生成专用函数(如固定税率、单位换算)。
- 函数组合:便于将多个小函数组合成复杂逻辑(如
compose(f, g)(x))。 - 延迟计算:分步传递参数,按需触发执行(如事件处理、条件满足后执行)。
优势:职责单一:
在函数式编程中,我们其实往往希望一个函数处理的问题尽可能的单一,而不是将一大堆的处理过程交给一个函数来处理;那么我们是否就可以将每次传入的参数在单一的函数中进行处理,处理完后在下一个函数中再使用处理后的结果;
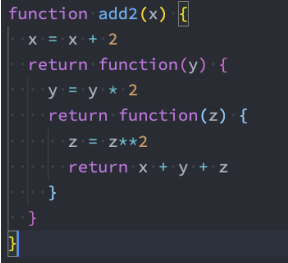
示例:每个函数只处理一件事
上面的案例做如下修改:传入的函数需要分别被进行如下处理:
第一个参数 + 2
第二个参数 * 2
第三个参数 ** 2
优势:参数复用:
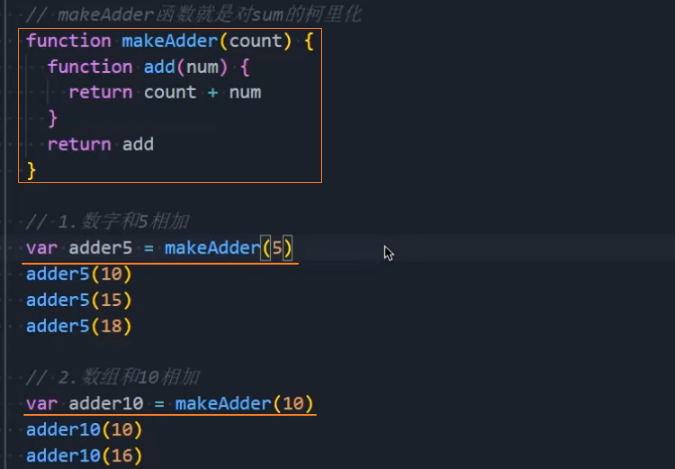
另外一个使用柯里化的场景是可以帮助复用参数逻辑:
示例:工厂函数 makeAdder
makeAdder 函数要求我们传入一个 num(并且如果我们需要的话,可以在这里对 num 进行一些修改);
在之后使用返回的函数时,我们不需要再继续传入 num 了;
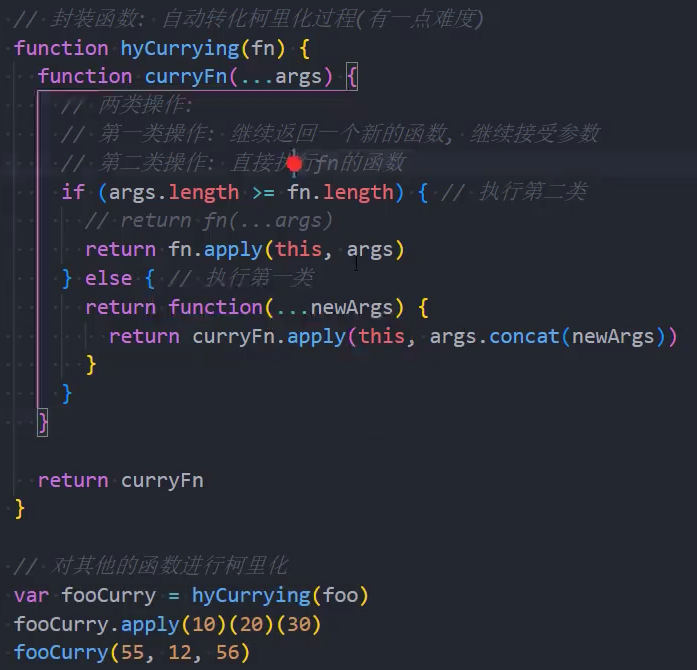
手写自动柯里化函数@
目前我们有将多个普通的函数,转成柯里化函数:
组合函数
组合函数概念的理解
组合函数(Compose Function):是在 JavaScript 开发过程中一种对函数的使用技巧、模式:
比如我们现在需要对某一个数据进行函数的调用,执行两个函数 fn1 和 fn2,这两个函数是依次执行的;
那么如果每次我们都需要进行两个函数的调用,操作上就会显得重复;
那么是否可以将这两个函数组合起来,自动依次调用呢?
这个过程就是对函数的组合,我们称之为组合函数;
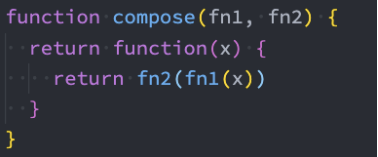
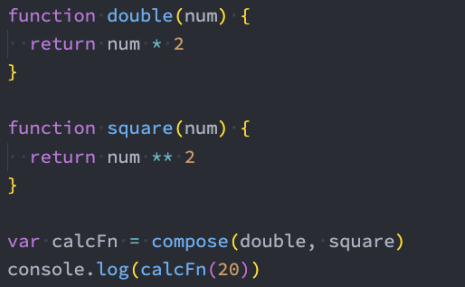
手写组合函数@
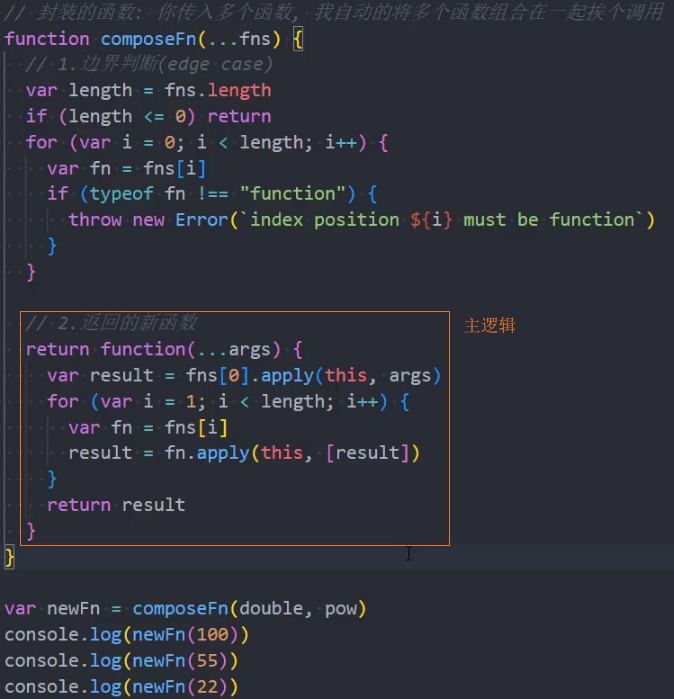
刚才我们实现的 compose 函数比较简单
我们需要考虑更加复杂的情况:比如传入了更多的函数,在调用 compose 函数时,传入了更多的参数:
with、eval
with语句的使用
with语句扩展一个语句的作用域链。
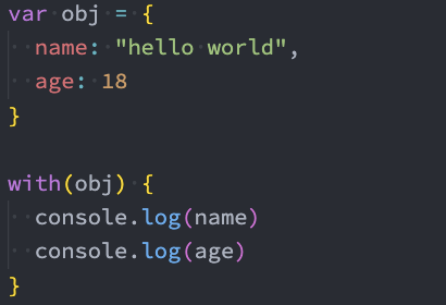
不建议使用 with 语句,因为它可能是混淆错误和兼容性问题的根源。
eval函数
内建函数 eval 允许执行一个代码字符串。
eval 是一个特殊的函数,它可以将传入的字符串当做 JavaScript 代码来运行;
eval 会将最后一句执行语句的结果,作为返回值;

不建议在开发中使用 eval:
eval 代码的可读性非常的差(代码的可读性是高质量代码的重要原则);
eval 是一个字符串,那么有可能在执行的过程中被刻意篡改,那么可能会造成被攻击的风险;
eval 的执行必须经过 JavaScript 解释器,不能被 JavaScript 引擎优化;
严格模式
认识严格模式
JavaScript 历史的局限性:
长久以来,JavaScript 不断向前发展且并未带来任何兼容性问题;
新的特性被加入,旧的功能也没有改变,这么做有利于兼容旧代码;
但缺点是 JavaScript 创造者的任何错误或不完善的决定也将永远被保留在 JavaScript 语言中;
在 ECMAScript5 标准中,JavaScript 提出了 严格模式(Strict Mode) 的概念:
严格模式很好理解,是一种具有限制性的 JavaScript 模式,从而使代码隐式的脱离了 ”懒散(sloppy)模式“;
支持严格模式的浏览器在检测到代码中有严格模式时,会以更加严格的方式对代码进行检测和执行;
严格模式对正常的 JavaScript 语义进行了一些限制:
严格模式通过 抛出错误 来消除一些原有的静默(silent)错误;
严格模式让JS 引擎在执行代码时可以进行更多的优化(不需要对一些特殊的语法进行处理);
严格模式禁用了在ECMAScript 未来版本中可能会定义的一些语法;
开启严格模式
那么如何开启严格模式呢?严格模式支持粒度化迁移:
可以支持在js 文件中开启严格模式;
也支持对某一个函数开启严格模式;

严格模式通过在文件或者函数开头使用 use strict 来开启。
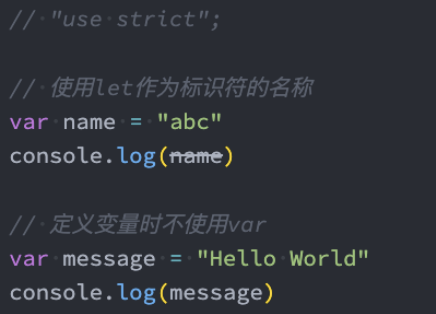
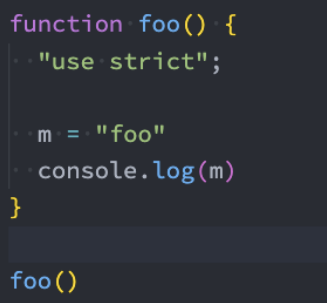
注意:
没有类似于 "no use strict" 这样的指令可以使程序返回默认模式。
现代 JavaScript 支持 “class” 和 “module” ,它们会自动启用 use strict;
严格模式限制
JavaScript 被设计为新手开发者更容易上手,所以有时候本来错误语法,被认为也是可以正常被解析的;但是这种方式可能给带来留下来安全隐患;在严格模式下,这种失误就会被当做错误,以便可以快速的发现和修正;
严格模式限制:这里我们来说几个严格模式下的严格语法限制:
1、无法意外的创建全局变量
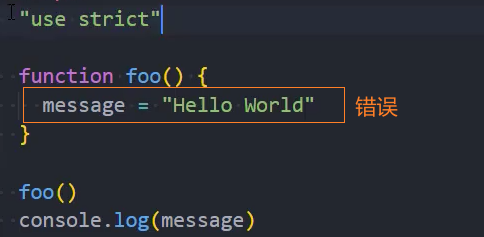
2、严格模式会使引起静默失败(silently fail,注:不报错也没有任何效果)的赋值操作抛出异常
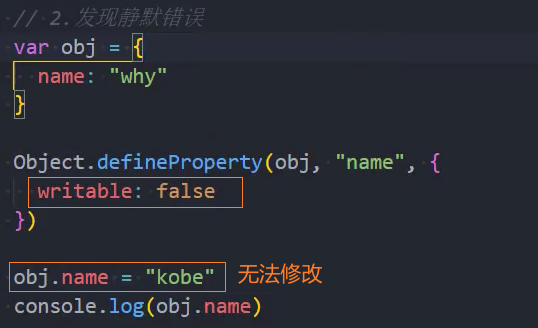
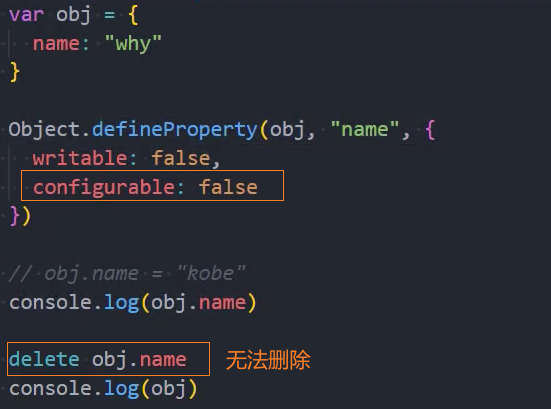
3、严格模式下试图删除不可删除的属性
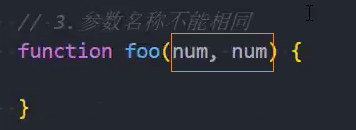
4、严格模式不允许函数参数有相同的名称
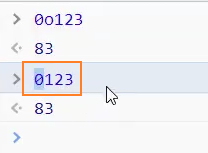
5、不允许 0 的八进制语法,要使用 0o
6、在严格模式下,不允许使用 with
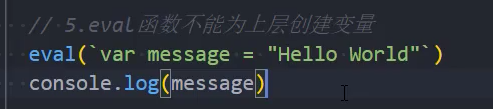
7、在严格模式下,eval 不能为上层引用(创建)变量
8、严格模式下,this 绑定不会默认转成对象,也不会绑定 window,而是 undefined
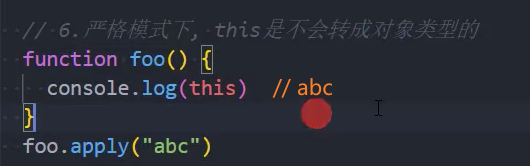
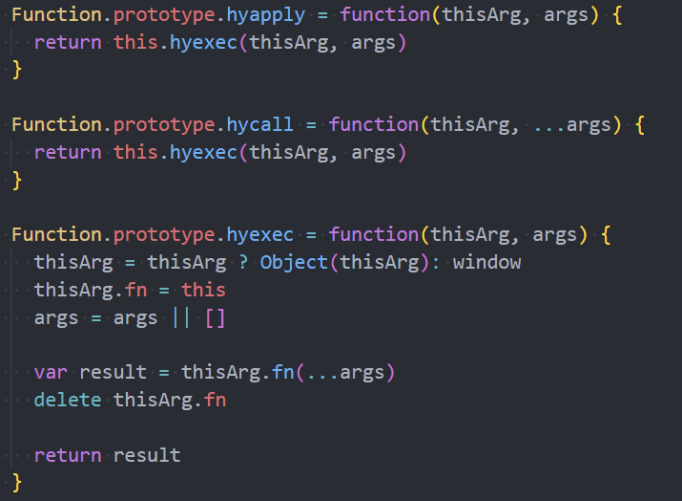
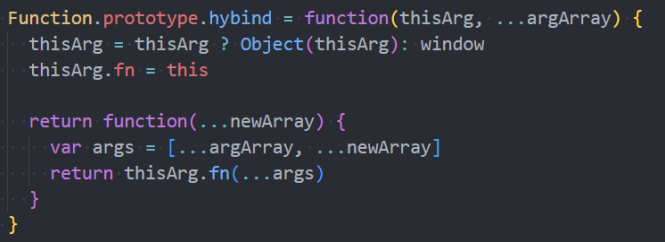
手写apply、call、bind函数实现(原型后)
接下来我们来实现一下 apply、call、bind 函数:
- 注意:我们的实现是练习函数、this、调用关系,不会过度考虑一些边界情况
underscore
underscore库的介绍
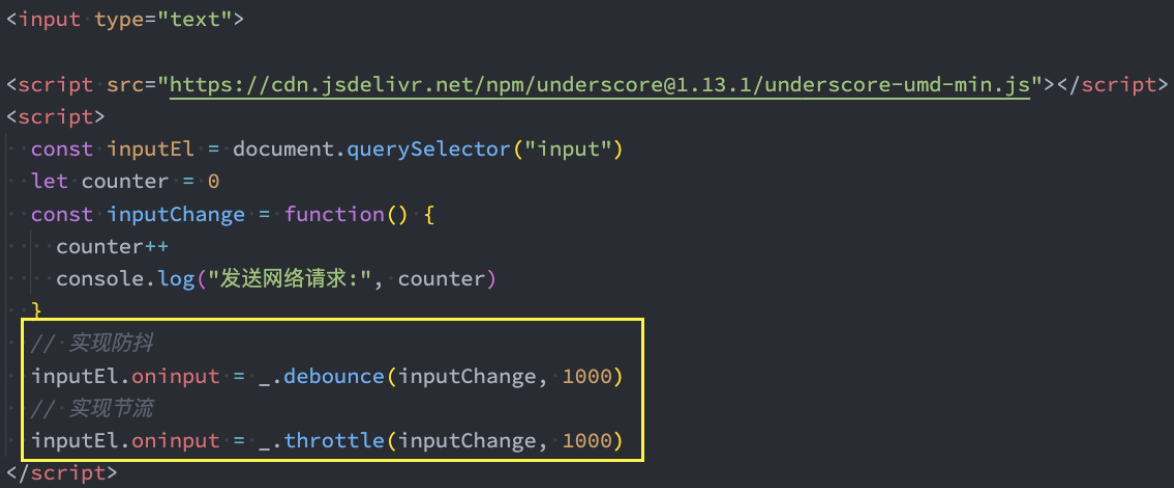
事实上我们可以通过一些第三方库来实现防抖操作:
lodash
underscore
这里使用underscore
我们可以理解成lodash是underscore的升级版,它更重量级,功能也更多;
但是目前我看到underscore还在维护,lodash已经很久没有更新了;
underscore的官网: https://underscorejs.org/
安装:
underscore的安装有很多种方式:
下载underscore,本地引入;
通过CDN直接引入;
通过包管理工具(npm)管理安装;
这里我们直接通过CDN:
<script src="https://cdn.jsdelivr.net/npm/underscore@1.13.1/underscore-umd-min.js"></script>underscore实现防抖和节流