S03-07 JS-高级-JS原理
[TOC]
浏览器渲染原理@
网页的解析过程
大家有没有深入思考过:一个网页 URL 从输入到浏览器中,到显示经历过怎么样的解析过程呢?
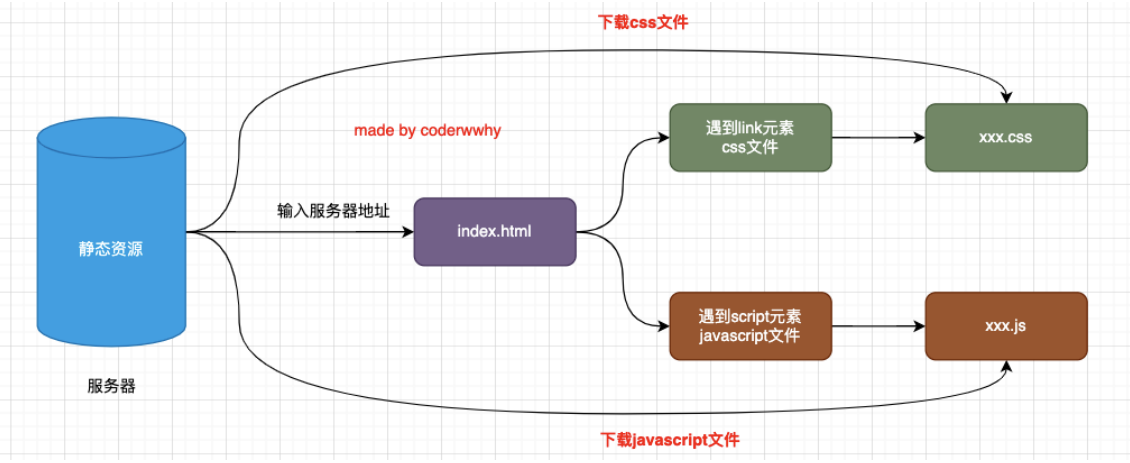
要想深入理解下载的过程,我们还要先理解,一个 index.html 被下载下来后是如何被解析和显示在浏览器上的.
浏览器渲染流程
浏览器内核
常见的浏览器内核有
Trident ( 三叉戟):IE、360 安全浏览器、搜狗高速浏览器、百度浏览器、UC 浏览器;
Gecko( 壁虎) :Mozilla Firefox;
Presto(急板乐曲)-> Blink (眨眼):Opera
Webkit :Safari、360 极速浏览器、搜狗高速浏览器、移动端浏览器(Android、iOS)
Webkit -> Blink :Google Chrome,Edge

我们经常说的浏览器内核指的是浏览器的排版引擎:
排版引擎(layout engine),也称为浏览器引擎(browser engine)、页面渲染引擎(rendering engine)或样版引擎。
也就是一个网页下载下来后,就是由我们的渲染引擎来帮助我们解析的。
渲染流程
渲染引擎在拿到一个页面后,如何解析整个页面并且最终呈现出我们的网页呢?
我们之前学习过下面的这幅图,现在让我们更加详细的学习它的过程;
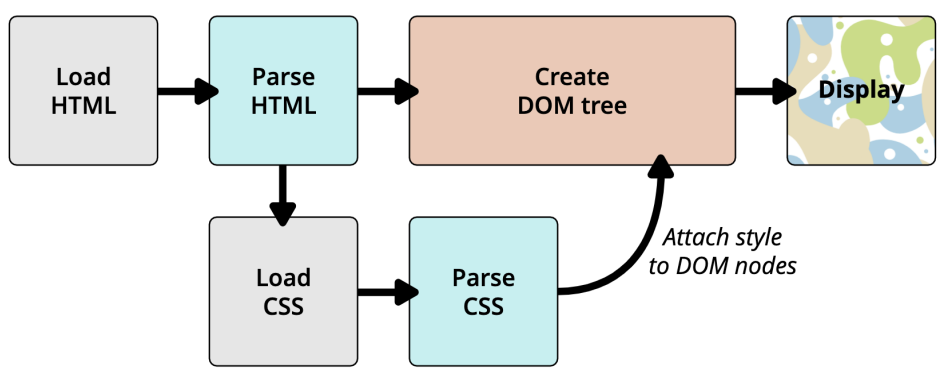
更详细的解析过程如下:
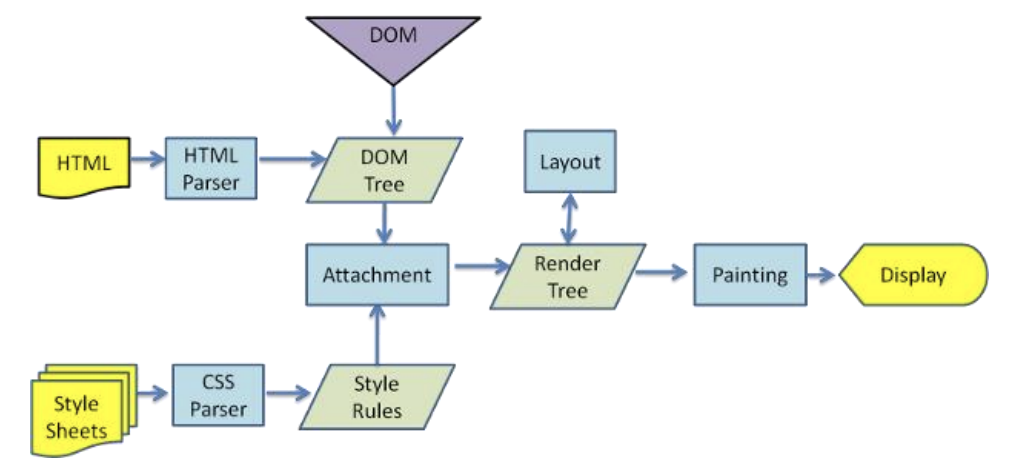
https://www.html5rocks.com/en/tutorials/internals/howbrowserswork
https://juejin.cn/post/6844903704206786573
回流和重绘解析
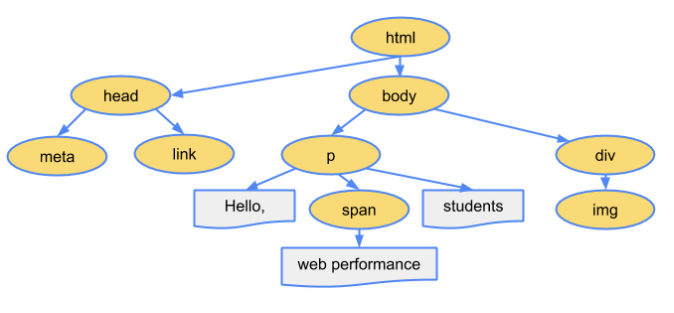
解析一:解析 HTML
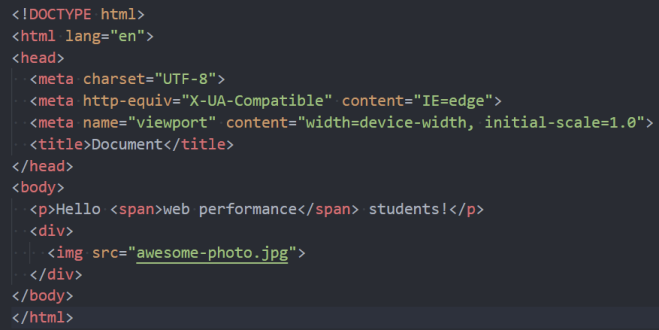
因为默认情况下服务器会给浏览器返回 index.html 文件,所以解析 HTML 是所有步骤的开始:
解析 HTML,会构建 DOM Tree:
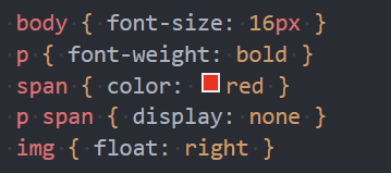
解析二:生成 CSS 规则
在解析 HTML 的过程中,如果遇到 CSS 的 link 元素,那么会由浏览器负责下载对应的 CSS 文件:
*注意:*下载 CSS 文件是不会影响 DOM 的解析的;
浏览器下载完 CSS 文件后,就会对 CSS 文件进行解析,解析出对应的规则树:
我们可以称之为 CSSOM(CSS Object Model,CSS 对象模型);
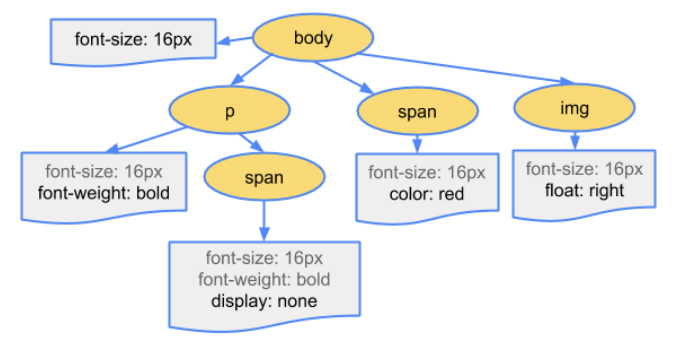
解析三:构建 Render Tree
当有了 DOM Tree 和 CSSOM Tree 后,就可以两个结合来构建 Render Tree 了
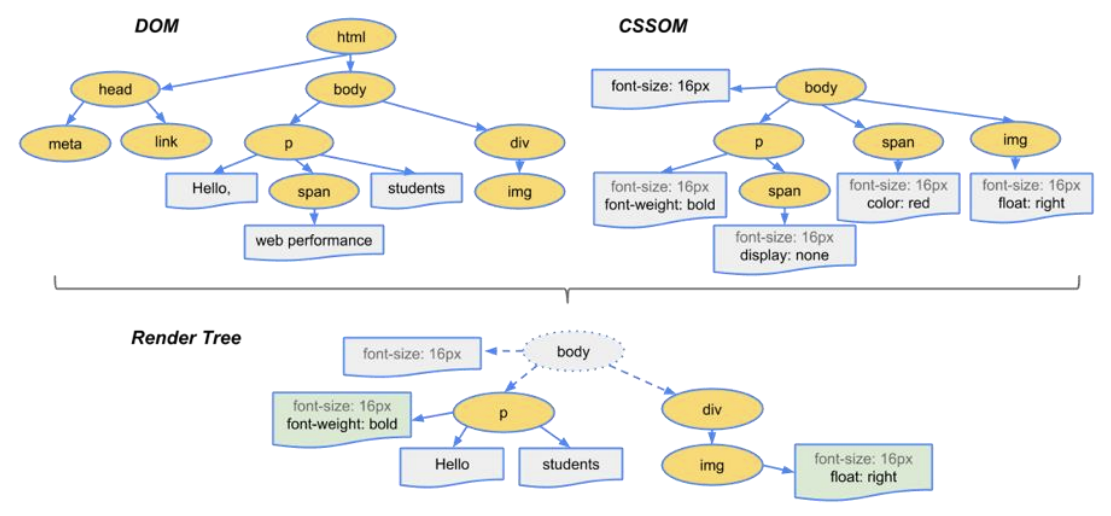
注意: link 元素不会阻塞 DOM Tree的构建过程,但是会阻塞 Render Tree的构建过程。这是因为 Render Tree 在构建时,需要对应的 CSSOM Tree;
注意: Render Tree 和 DOM Tree 并不是一一对应的关系,比如对于display 为 none的元素,压根不会出现在 render tree 中;
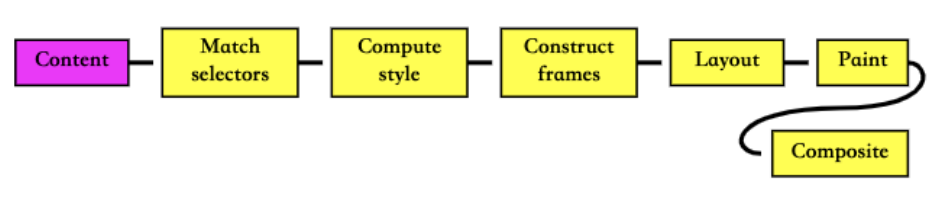
解析四:布局和绘制
第四步是在渲染树(Render Tree)上运行布局(Layout)以计算每个节点的几何体。
渲染树会表示显示哪些节点以及其他样式,但是不表示每个节点的尺寸、位置等信息;
布局是确定呈现树中所有节点的宽度、高度和位置信息;
第五步是将每个节点绘制(Paint)到屏幕上
在绘制阶段,浏览器将布局阶段计算的每个 frame 转为屏幕上实际的像素点;
包括将元素的可见部分进行绘制,比如文本、颜色、边框、阴影、替换元素(比如 img)
回流和重绘
回流(reflow)
理解回流 reflow:(也可以称之为重排)
第一次确定节点的大小和位置,称之为布局(layout)。
之后对节点的大小、位置修改重新计算称之为回流。
引起回流的情况:
比如DOM 结构发生改变(添加新的节点或者移除节点);
比如改变了布局(修改了 width、height、padding、font-size 等值)
比如窗口 resize(修改了窗口的尺寸等)
比如调用getComputedStyle方法获取尺寸、位置信息;
重绘(repaint)
理解重绘 repaint:
第一次渲染内容称之为绘制(paint)。
之后重新渲染称之为重绘。
引起重绘的情况:
- 比如修改背景色、文字颜色、边框颜色、样式等;
回流一定会引起重绘,所以回流是一件很消耗性能的事情。
避免回流:
所以在开发中要尽量避免发生回流:
1、修改样式时尽量一次性修改
- 比如通过 cssText 修改,比如通过添加 class 修改
2、尽量避免频繁的操作 DOM
- 我们可以在一个 DocumentFragment 或者父元素中将要操作的 DOM 操作完成,再一次性的操作;
3、尽量避免通过 getComputedStyle 获取尺寸、位置等信息;
4、对某些元素使用 position 的absolute或者fixed
- 并不是不会引起回流,而是开销相对较小,不会对其他元素造成影响。
合成和性能优化
特殊解析:composite 合成
绘制的过程,可以将布局后的元素绘制到多个合成图层中。这是浏览器的一种优化手段;
默认情况下,标准流中的内容都是被绘制在同一个图层(Layer)中的;
而一些特殊的属性,会创建一个新的合成层( CompositingLayer ),并且新的图层可以利用 GPU 来加速绘制;因为每个合成层都是单独渲染的;
那么哪些属性可以形成新的合成层呢?常见的一些特殊属性:
3D transforms
video、canvas、iframe
opacity 动画转换时;
position: fixed
will-change:一个实验性的属性,提前告诉浏览器元素可能发生哪些变化;
animation 或 transition 设置了 opacity、transform;
分层确实可以提高性能,但是它以内存管理为代价,因此不应作为 web 性能优化策略的一部分过渡使用。

script 元素阻塞
我们现在已经知道了页面的渲染过程,但是 JavaScript 在哪里呢?
事实上,浏览器在解析 HTML 的过程中,遇到了 script 元素是不能继续构建 DOM 树的;
它会停止继续构建,首先下载 JavaScript 代码,并且执行 JavaScript 的脚本;
只有等到 JavaScript 脚本执行结束后,才会继续解析 HTML,构建 DOM 树;
为什么要这样做呢?
这是因为JavaScript的作用之一就是操作 DOM,并且可以修改 DOM;
如果我们等到 DOM 树构建完成并且渲染再执行 JavaScript,会造成严重的回流和重绘,影响页面的性能;
所以会在遇到 script 元素时,优先下载和执行 JavaScript 代码,再继续构建 DOM 树;
但是这个也往往会带来新的问题,特别是现代页面开发中:
在目前的开发模式中(比如 Vue、React),脚本往往比 HTML 页面更“重”,处理时间需要更长;
所以会造成页面的解析阻塞,在脚本下载、执行完成之前,用户在界面上什么都看不到;
为了解决这个问题,script 元素给我们提供了两个属性(attribute):defer和async。
defer 和 async 属性
defer 属性
defer属性告诉浏览器不要等待脚本下载,而是继续解析 HTML,构建 DOM Tree。
特点:
1、脚本会由浏览器来进行下载,但是不会阻塞 DOM Tree的构建过程;
2、defer 脚本中可以获取到 DOM 元素
3、如果脚本提前下载好了,它会等待 DOM Tree 构建完成,在DOMContentLoaded 事件之前先执行 defer 中的代码;
所以 DOMContentLoaded 总是会等待 defer 中的代码先执行完成。
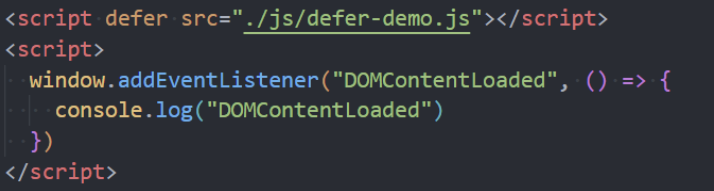
4、多个带 defer 的脚本是可以保持正确的顺序执行的。

5、从某种角度来说,defer 可以提高页面的性能,并且推荐放到 head元素中;
6、*注意:*defer 仅适用于外部脚本,对于内嵌 script 默认内容会被忽略。
async 属性
async 特性与 defer 有些类似,它也能够让脚本不阻塞页面。
特点:
async 是让一个脚本完全独立的:
1、浏览器不会因 async 脚本而阻塞(与 defer 类似);
2、async 脚本不能保证顺序,它是独立下载、独立运行,不会等待其他脚本;
3、async不能保证在 DOMContentLoaded 之前或者之后执行;
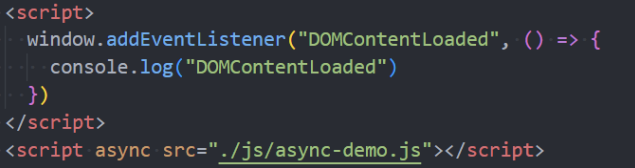
defer 和 async 的应用:
defer 通常用于需要在文档解析后操作 DOM 的 JavaScript 代码,并且对多个 script 文件有顺序要求的;
async 通常用于独立的脚本,对其他脚本,甚至 DOM 没有依赖的;
JS运行原理@
V8引擎原理
JS代码的执行
JavaScript 代码下载好之后,是如何一步步被执行的呢?
浏览器内核组成:我们知道,浏览器内核 是由两部分组成的,以 webkit 为例:
WebCore:负责 HTML 解析、布局、渲染等等相关的工作;
JavaScriptCore:解析、执行 JavaScript 代码;
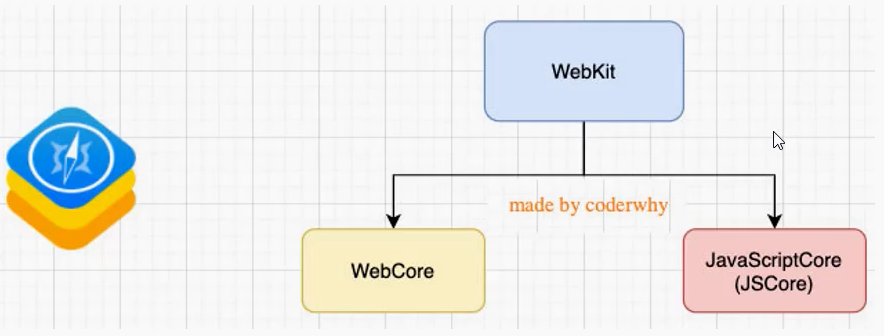
另外一个强大的 JavaScript 引擎就是 V8 引擎。
V8引擎-执行原理
V8:我们来看一下官方对 V8 引擎的定义:
V8 是用 C ++编写的 Google 开源高性能 JavaScript 和 WebAssembly 引擎,它用于Chrome和Node.js等。
它实现ECMAScript和WebAssembly规范,并在 Windows 7 或更高版本,macOS 10.12+和使用 x64,IA-32,ARM 或 MIPS 处理器的 Linux 系统上运行。
V8 可以独立运行,也可以嵌入到任何 C++ 应用程序中。
WebAssembly:是一种二进制指令格式,专为Web设计的低级编程语言,可在现代浏览器中高性能执行。它不是替代 JavaScript,而是作为其补充,用于处理需要接近原生性能的任务(如游戏、音视频处理、科学计算等)。
总结: 高性能、跨平台、可独立运行
V8引擎-架构
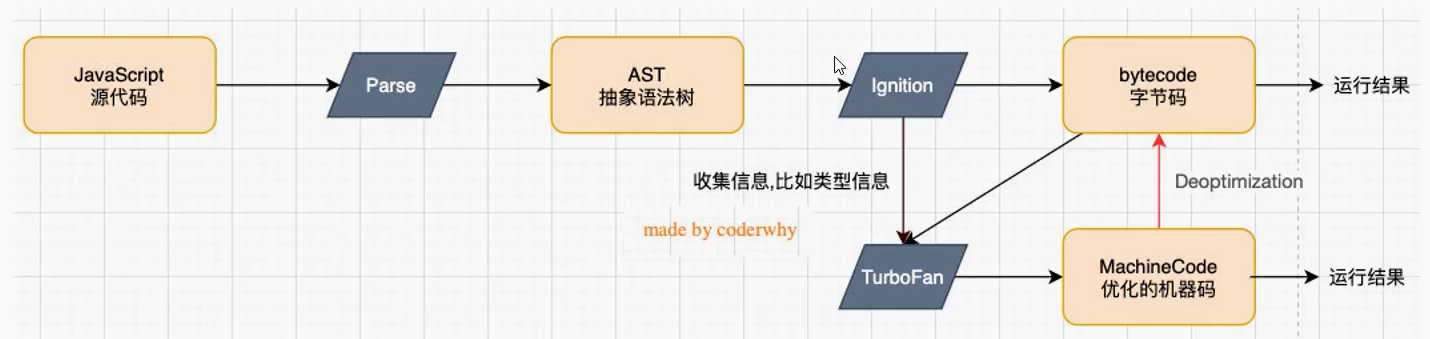
V8 引擎本身的源码非常复杂,大概有超过100w 行 C++代码,通过了解它的架构,我们可以知道它是如何对 JavaScript 执行的:
Parse:模块会将 JavaScript 代码转换成 AST(抽象语法树),这是因为解释器并不直接认识 JavaScript 代码;
如果函数没有被调用,那么是不会被转换成 AST 的;
Parse 的 V8 官方文档:https://v8.dev/blog/scanner
Ignition:是一个解释器,会将 AST 转换成 字节码(ByteCode)
同时会收集 TurboFan 优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算);
如果函数只调用一次,Ignition 会解释执行 ByteCode;
Ignition 的 V8 官方文档:https://v8.dev/blog/ignition-interpreter
TurboFan:是一个优化编译器,可以将字节码编译为 CPU 可以直接执行的机器码(MachineCode);
如果一个函数被多次调用,那么就会被标记为热点函数,那么就会经过 TurboFan转换成优化的机器码,提高代码的执行性能;
但是,机器码实际上也会被去优化(Deoptimization)为 ByteCode,这是因为如果后续执行函数的过程中,类型发生了变化(比如 sum 函数原来执行的是 number 类型,后来执行变成了 string 类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码;
TurboFan 的 V8 官方文档:https://v8.dev/blog/turbofan-jit
相关概念:
- 抽象语法树(Abstract Syntax Tree, AST)
- 字节码(ByteCode):是介于高级编程语言与机器码之间的中间代码,本质是一套虚拟指令集,需由虚拟机(VM)或运行时环境解释/编译执行。它是现代编程语言实现跨平台、高效执行的核心技术方案。
- 机器码(MachineCode):是计算机CPU可直接执行的底层指令,由二进制数字(0和1)组成,直接对应处理器的硬件操作。它是所有软件运行的最终形态,是连接软件与硬件的终极桥梁。
抽象语法树
抽象语法树(Abstract Syntax Tree, AST):是计算机科学中用于表示代码结构的树状数据结构,它是代码的抽象化表达,去除了不重要的语法细节(如分号、括号位置等),只保留代码的逻辑结构和语义关系,是编译器、解释器、代码分析工具的核心中间表示形式。
关键特性:
- 结构化表示:用树形结构分层表达代码逻辑(如函数、循环、表达式等)
- 去语法糖:忽略具体语法符号(如
{}、;等),保留核心逻辑 - 语言无关性:不同编程语言的AST结构可能相似,便于跨语言分析
- 可遍历性:通过深度优先搜索(DFS)等算法遍历节点
AST生成过程:
以JavaScript代码 const sum = (a, b) => a + b; 为例:
词法分析(Lexical Analysis) 将代码拆分为词法单元(Tokens):
json[ { type: 'Keyword', value: 'const' }, { type: 'Identifier', value: 'sum' }, { type: 'Punctuator', value: '=' }, { type: 'Punctuator', value: '(' }, { type: 'Identifier', value: 'a' }, // ... 其他tokens ]语法分析(Syntax Analysis) 根据语法规则将Tokens转换为AST:
json{ "type": "VariableDeclaration", "declarations": [{ "type": "VariableDeclarator", "id": { "type": "Identifier", "name": "sum" }, "init": { "type": "ArrowFunctionExpression", "params": [ { "type": "Identifier", "name": "a" }, { "type": "Identifier", "name": "b" } ], "body": { "type": "BinaryExpression", "operator": "+", "left": { "type": "Identifier", "name": "a" }, "right": { "type": "Identifier", "name": "b" } } } }], "kind": "const" }
AST核心节点类型:
| 节点类型 | 描述 | 示例代码片段 |
|---|---|---|
Program | 整个程序的根节点 | 任何完整代码 |
VariableDeclaration | 变量声明 | let x = 10; |
FunctionDeclaration | 函数声明 | function foo() {} |
IfStatement | 条件语句 | if (condition) {...} |
ForStatement | for循环 | for (let i=0; i<5; i++) |
BinaryExpression | 二元运算表达式 | a + b |
CallExpression | 函数调用 | console.log() |
Literal | 字面量 | 3 |
应用场景:
代码编译/转译
- Babel将ES6+代码转换为ES5(通过AST分析修改)
- TypeScript编译器检查类型错误
js// Babel处理流程 源代码 → AST → 插件修改AST → 生成新代码代码静态分析
- ESLint检查代码规范
- Webpack进行依赖分析
js// ESLint规则示例:禁止console if (node.type === 'CallExpression' && node.callee.object?.name === 'console') { reportError('禁止使用console'); }代码格式化
- Prettier通过AST重新生成标准化代码
- 自动修复工具(如VS Code的快速修复)
代码混淆/压缩
- 变量重命名(
longVariableName → a) - 删除未使用代码(Tree Shaking)
- 变量重命名(
智能开发工具
- 代码自动补全(分析上下文AST)
- 重构工具(如提取函数、变量重命名)
对比具体语法树(CST):
| 对比维度 | AST(抽象语法树) | CST(具体语法树) |
|---|---|---|
| 节点内容 | 只保留关键逻辑节点 | 包含所有语法细节(如标点符号、括号) |
| 存储空间 | 较小 | 较大 |
| 使用场景 | 编译器优化、代码转换 | 语法高亮、代码格式化 |
| 示例对比 | a + b → BinaryExpression | a + b → Identifier(+)Identifier |
示例:AST修改实践
将代码 let x = 1 + 2; 优化为 let x = 3;:
// 原始AST片段
{
type: 'VariableDeclarator',
id: { type: 'Identifier', name: 'x' },
init: {
type: 'BinaryExpression',
operator: '+',
left: { type: 'Literal', value: 1 },
right: { type: 'Literal', value: 2 }
}
}
// 修改后的AST
{
type: 'VariableDeclarator',
id: { type: 'Identifier', name: 'x' },
init: { type: 'Literal', value: 3 }
}作用:
- 解耦语法与逻辑:同一逻辑的不同语法写法可生成相同AST(如
a+b与a + b) - 简化处理:避免直接操作字符串的复杂性
- 跨平台能力:不同工具链通过AST交换代码信息
- 性能优化:基于AST的静态分析比运行时分析更高效
V8 引擎-Parse过程
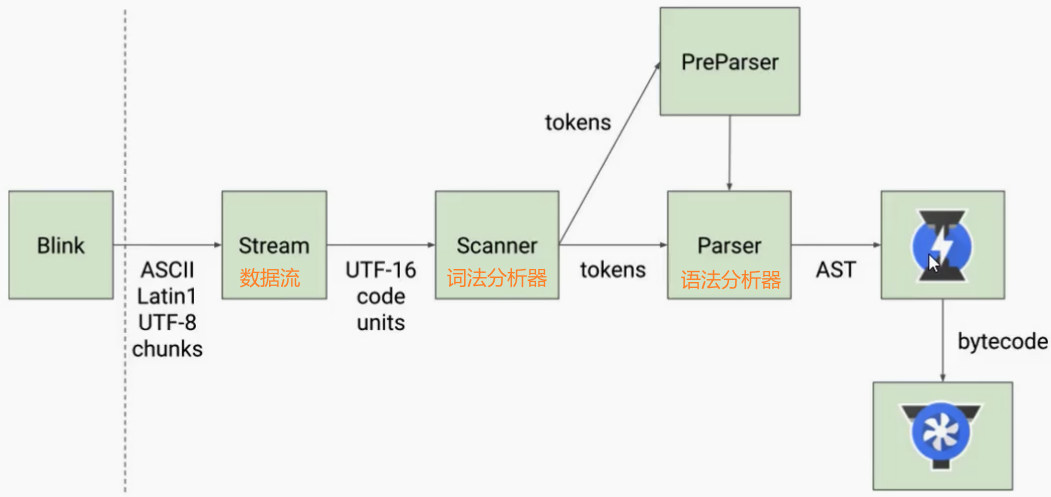
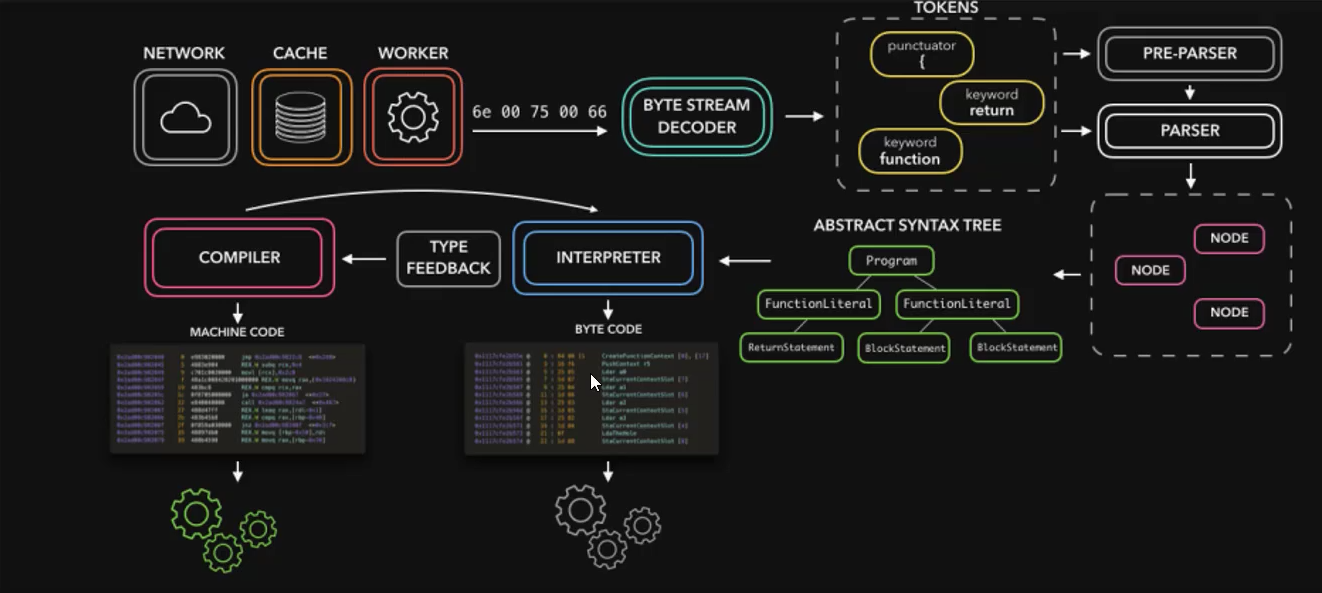
Parse流程:
源码传递与编码转换
Blink(浏览器渲染引擎)将JavaScript源码传递给V8引擎,由Stream模块处理源码并进行编码转换(如UTF-8解码)。词法分析
Scanner对源码进行词法分析,将字符流转换为Tokens。- 例如:
var a = 1;→ 分解为var、a、=、1、;等Token。
- 例如:
语法分析生成AST
Tokens通过语法分析转换为抽象语法树(AST),分为两种解析方式:
- Parser(全量解析):直接将Tokens转换为完整的AST。
- PreParser(预解析):仅部分解析,生成简化版AST,用于快速检查和优化。
后续流程
- AST生成后,由V8的
Ignition解释器转换为字节码并执行。 - 字节码可通过
TurboFan编译器进一步优化为机器码,提高执行效率(属代码执行阶段,非解析过程)。
- AST生成后,由V8的
PreParser的作用与原因:
核心目的:性能优化
- 减少初始解析时间:并非所有代码都需要立即执行(如未调用的函数),避免全量解析提升加载效率。
- 语法错误预检:快速识别语法错误,无需等待执行阶段。
延迟解析(Lazy Parsing)
对暂未执行的函数(如嵌套函数)进行预解析,仅提取关键信息(参数、函数体位置等)。
jsfunction outer() { function inner() { /* 预解析 */ } }inner函数在outer调用前仅预解析,全量解析推迟到inner实际调用时。
资源节省
- 避免生成完整AST和字节码,减少内存占用和CPU消耗。
JS执行上下文
ECMA版本说明
在 ECMA 早期的版本中(ECMAScript3),代码的执行流程的术语和 ECMAScript5 以及之后的术语会有所区别:
目前网上大多数流行的说法都是基于ECMAScript3版本的解析,并且在面试时问到的大多数都是 ECMAScript3 的版本内容。
但是 ECMAScript3 终将过去, ECMAScript5必然会成为主流,所以最好也理解 ECMAScript5 甚至包括ECMAScript6 以及更好版本的内容;
事实上在TC39的最新描述中,和 ECMAScript5 之后的版本又出现了一定的差异;
那么我们课程按照如下顺序学习:
通过ECMAScript3中的概念学习JavaScript 执行原理、作用域、作用域链、闭包等概念;
通过ECMAScript5中的概念学习块级作用域、let、const等概念;
事实上,它们只是在对某些概念上的描述不太一样,在整体思路上都是一致的。
JS执行原理
假如我们有下面一段代码,它在 JavaScript 中是如何被执行的呢?
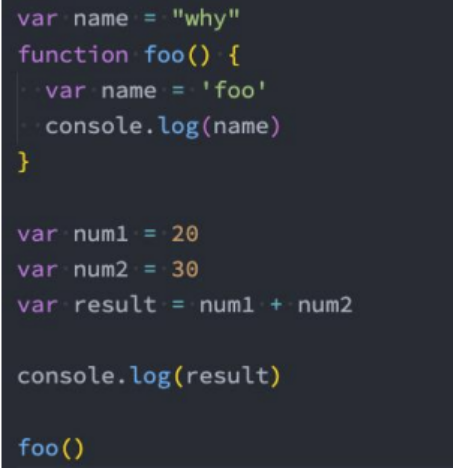
JS执行流程
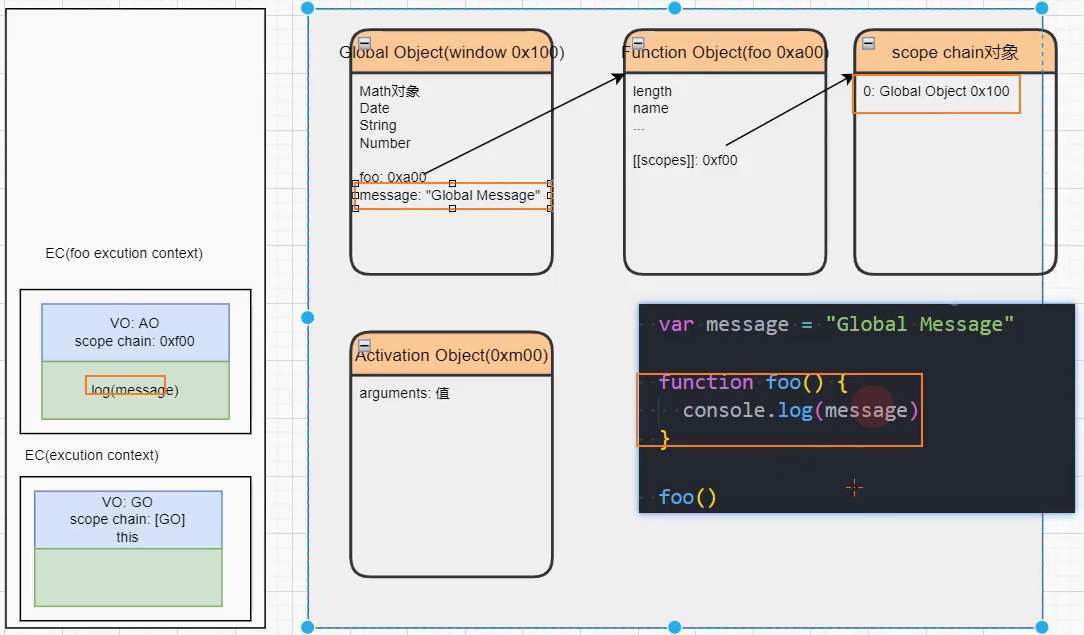
1、初始化全局对象 GO
2、事先存在一个执行上下文栈 ECS
3、执行全局代码:
在 ECS 中创建一个全局执行上下文 GEC
在 GEC 中创建 VO 对象,让它关联到 GO 对象
变量的作用域提升:在转成 AST 树时,会将变量、函数加入到 GO 中,但不赋值
4、执行函数代码:
- 在 ECS 中创建一个函数执行上下文 FEC
- 在 FEC 中创建 VO 对象,让它关联到 AO 对象
- 变量的作用域提升:在转成 AST 树时,会将变量、函数加入到 AO 中,但不赋值
JS执行-初始化全局对象GO
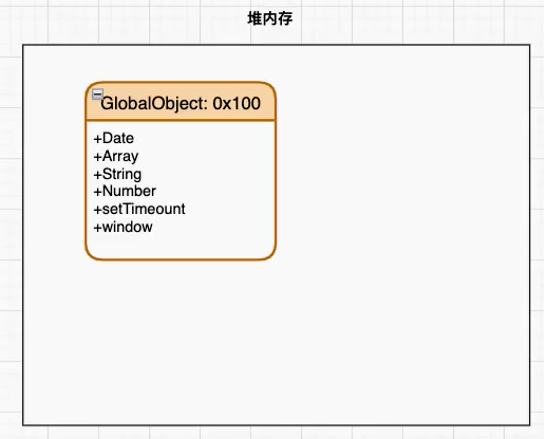
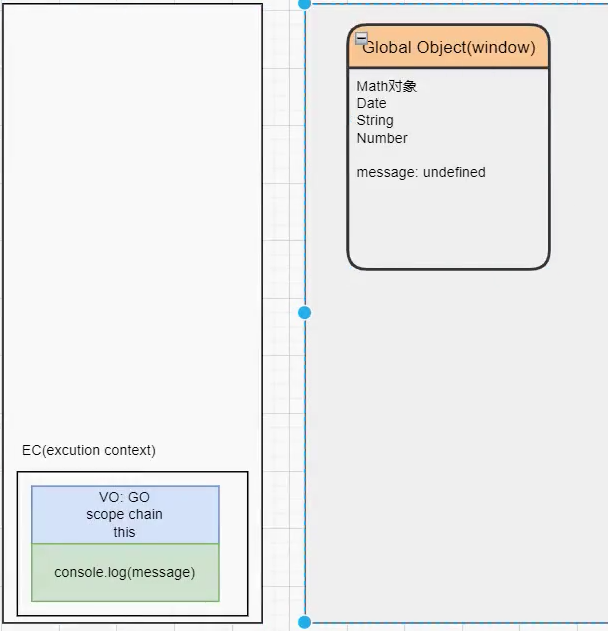
GO(Global Object):JS 引擎会在执行代码之前,在堆内存中创建一个全局对象 GO
该对象 所有的作用域(scope)都可以访问,在浏览器中该对象就是 window;
里面会包含 Date、Array、String、Number、setTimeout、setInterval 等等;
其中还有一个 window 属性指向自己;

JS执行-执行上下文EC
JS 引擎内部有一个执行上下文栈 ECS(Execution Context Stack),它是用于执行代码的调用栈。
那么现在它要执行谁呢?执行的是全局的代码块:
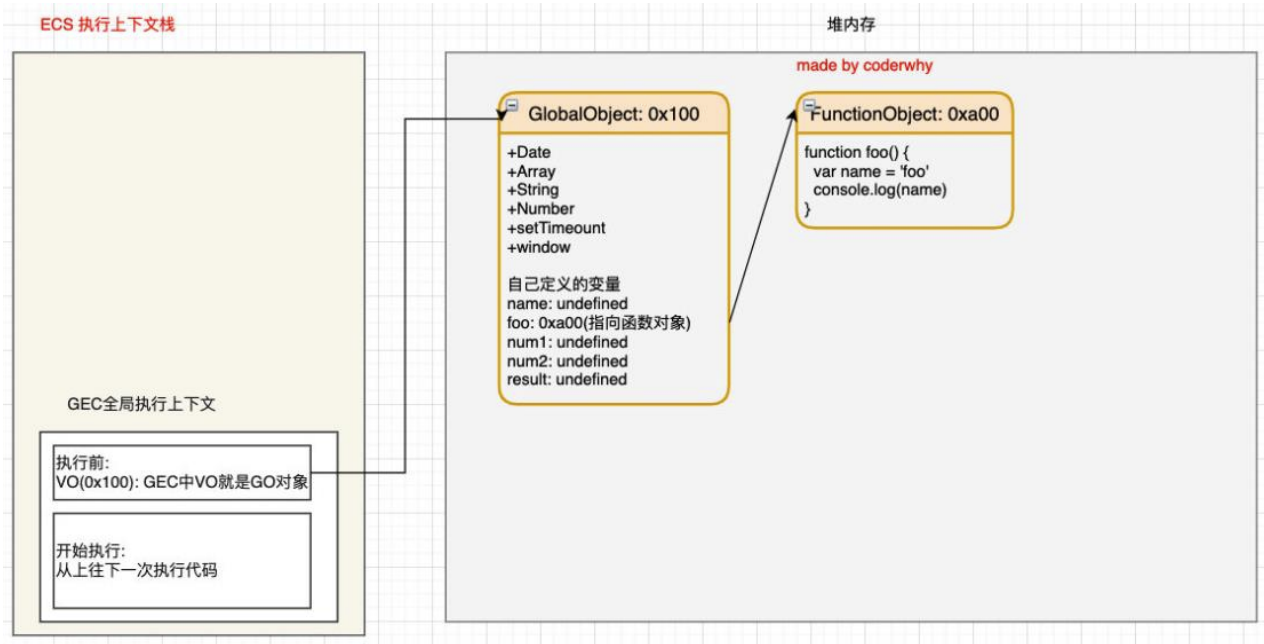
全局的代码块为了执行会构建一个 全局执行上下文 GEC(Global Execution Context);
GEC 会 被放入到 ECS 中 执行;
GEC 被放入到 ECS 中里面包含两部分内容:
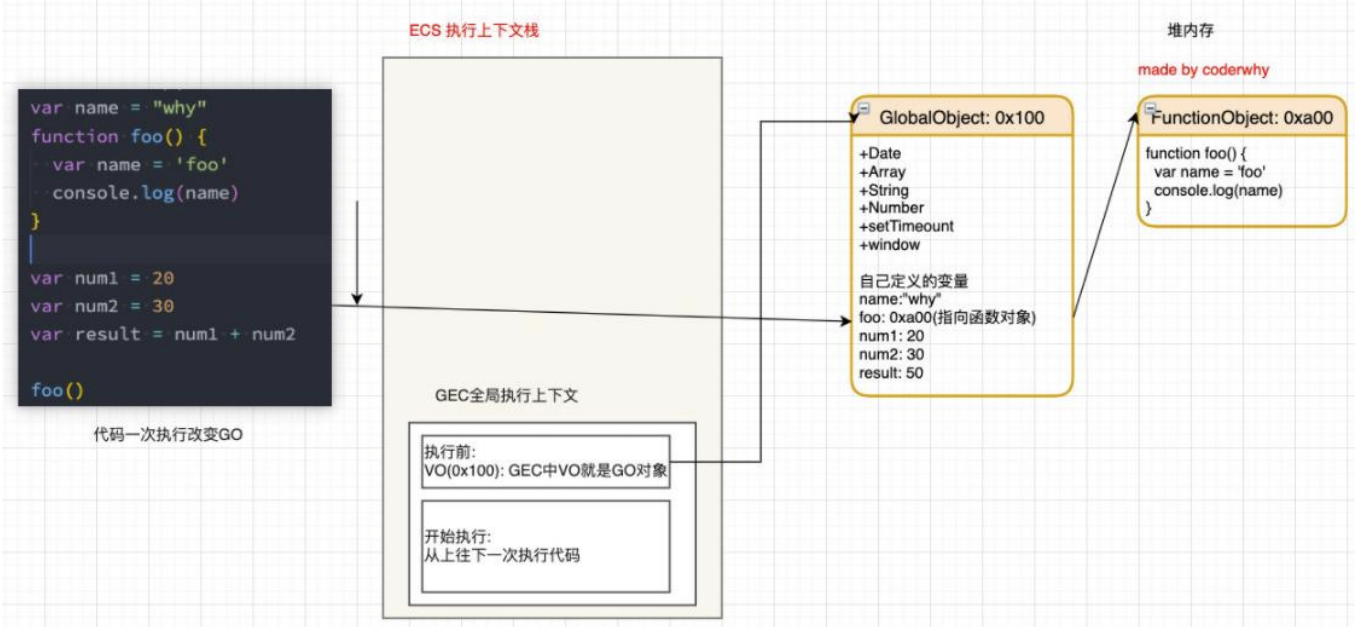
第一部分:作用域提升,在代码执行前,在 parser 转成 AST 的过程中,会将全局定义的变量、函数等加入到 GlobalObject 中,但是并不会赋值;这个过程也称之为变量的作用域提升(hoisting)
第二部分:在代码执行中,对变量赋值,或者执行其他的函数;

JS执行-认识VO对象
每一个执行上下文会关联一个变量对象 VO(Variable Object),变量和函数声明会被添加到这个 VO 对象中。

当全局代码被执行的时候,VO 就是 GO 对象了

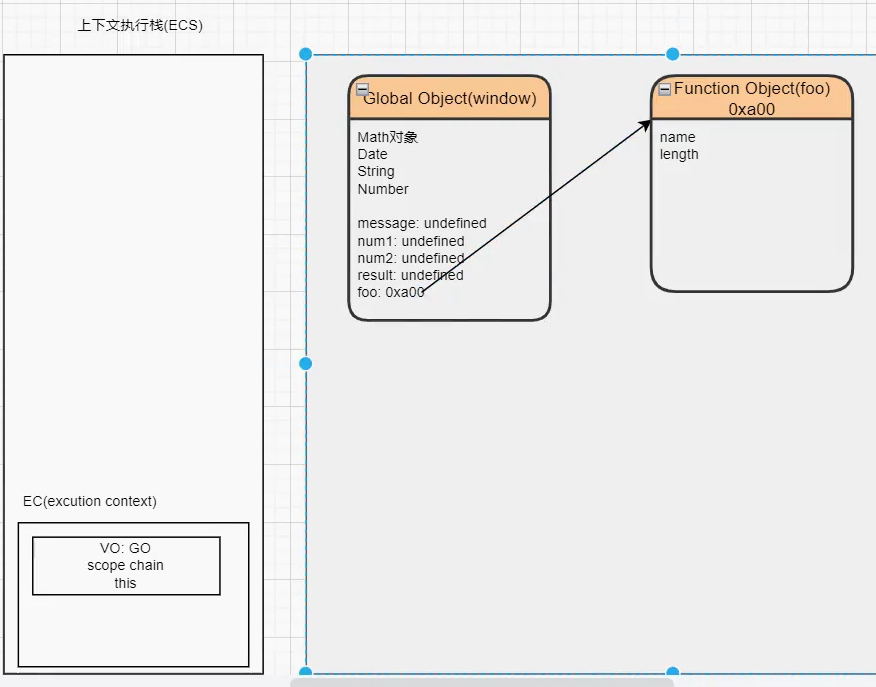
全局代码执行过程
全局代码执行过程(执行前)
全局代码执行过程(执行后)
函数代码执行过程
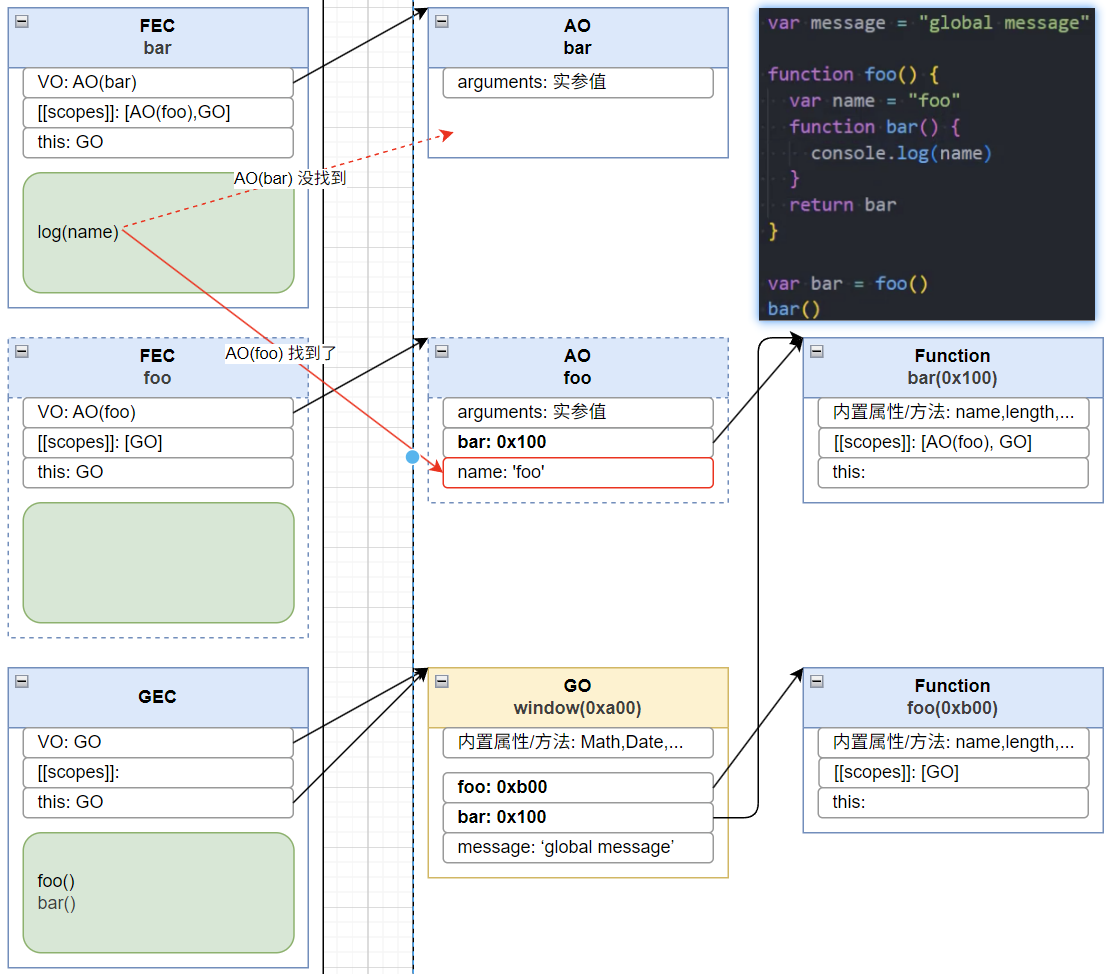
函数如何被执行呢?
在执行的过程中执行到一个函数时,就会根据函数体创建一个函数执行上下文 FEC(Functional Execution Context),并且压入到 EC Stack 中。
因为每个执行上下文都会关联一个 VO,那么函数执行上下文关联的 VO 是什么呢?
当进入一个函数执行上下文时,会创建一个AO 对象(Activation Object);
这个 AO 对象会使用arguments作为初始化,并且初始值是传入的参数;
这个 AO 对象会作为执行上下文的 VO 来存放变量的初始化;

函数的执行过程(执行前)
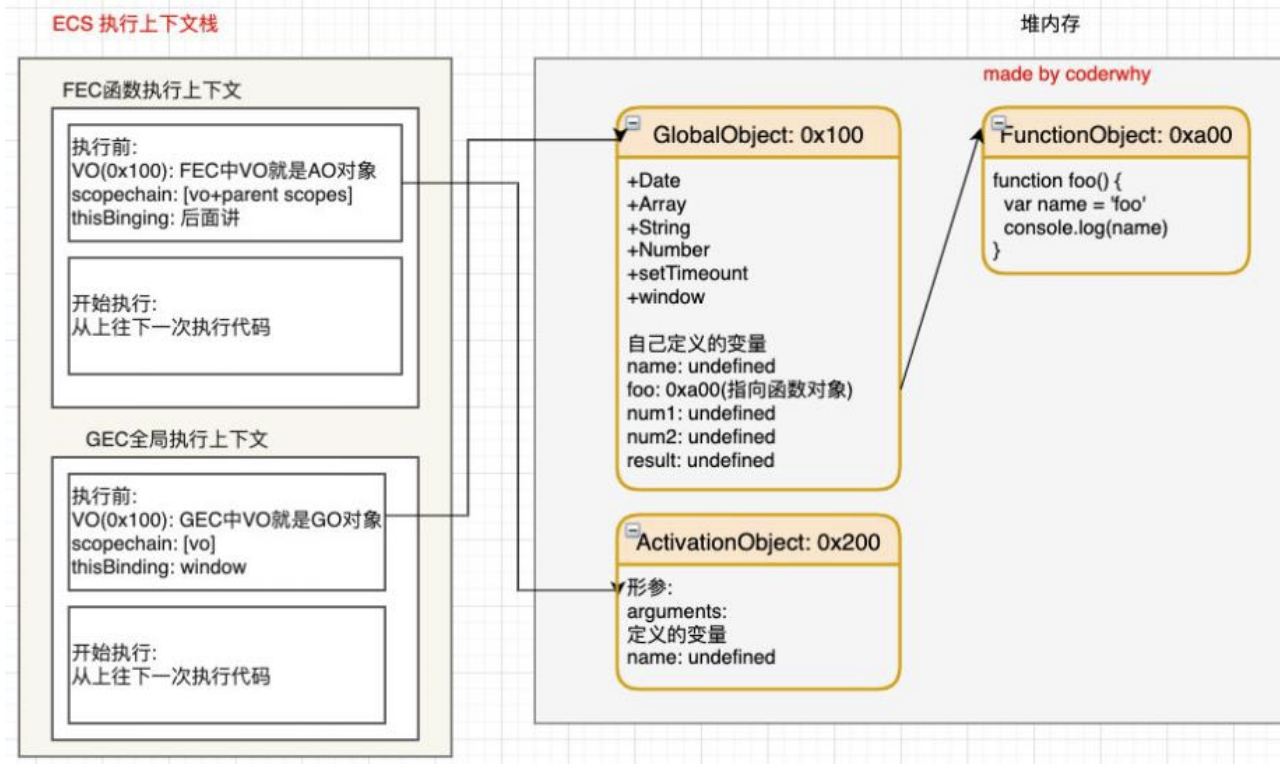
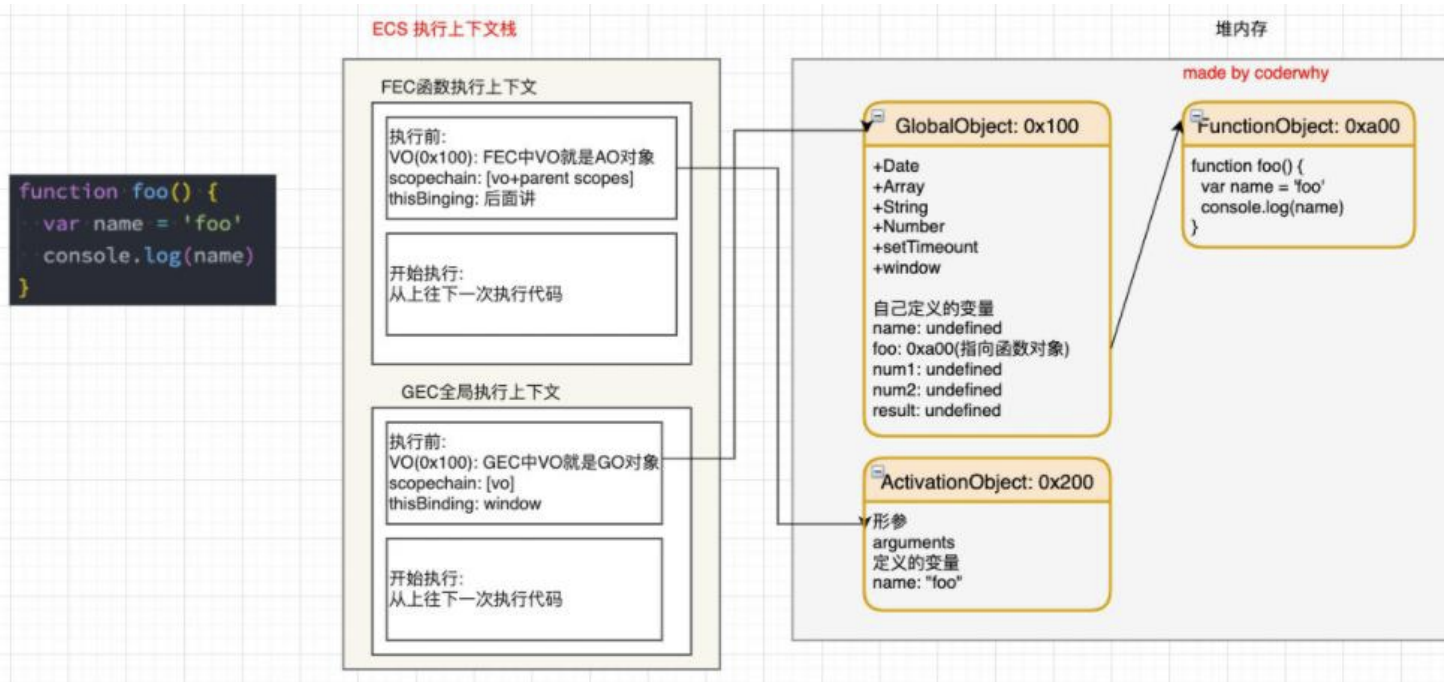
函数的执行过程(执行后)
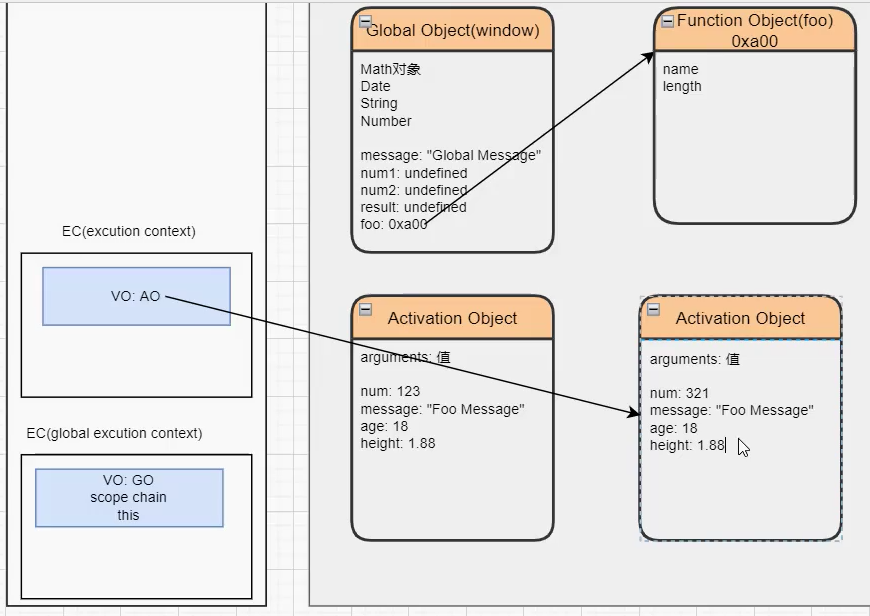
函数的多次执行
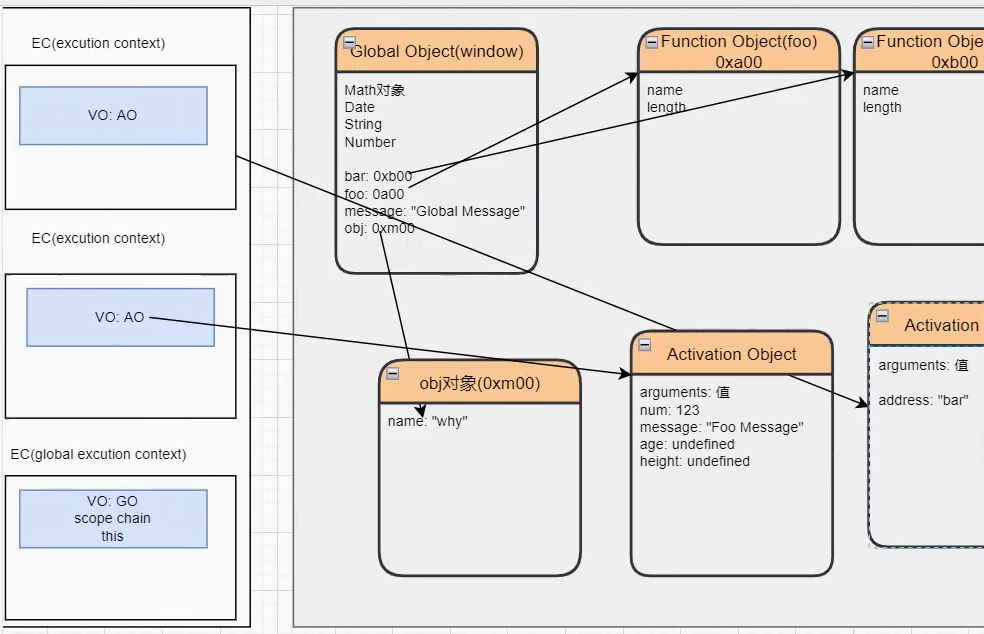
函数代码相互调用
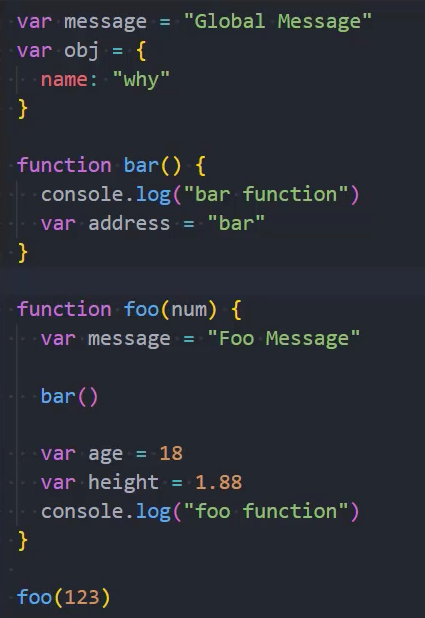
作用域和作用域链
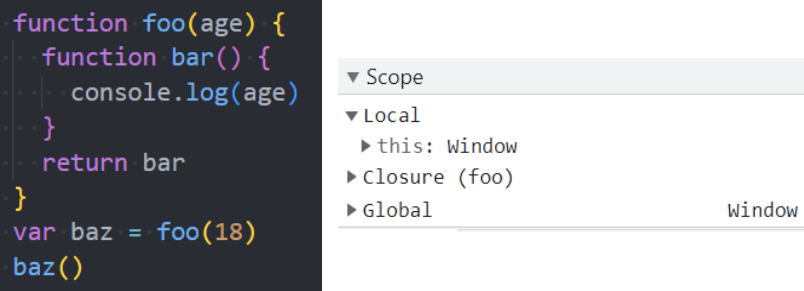
全局变量的查找
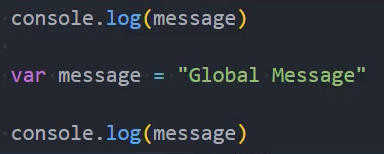
函数代码变量的查找
1、函数中有定义自己的 message
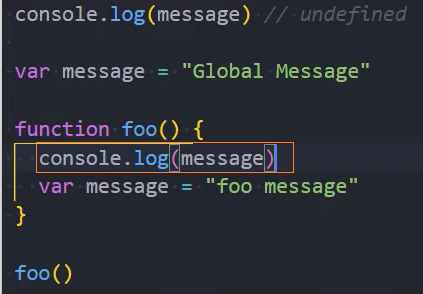
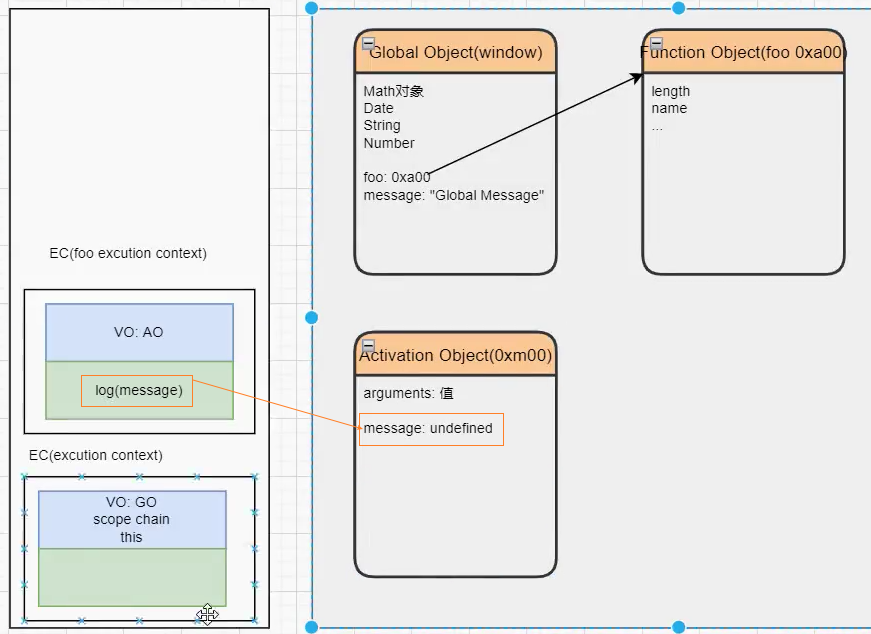
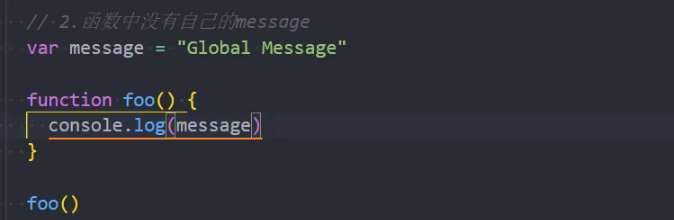
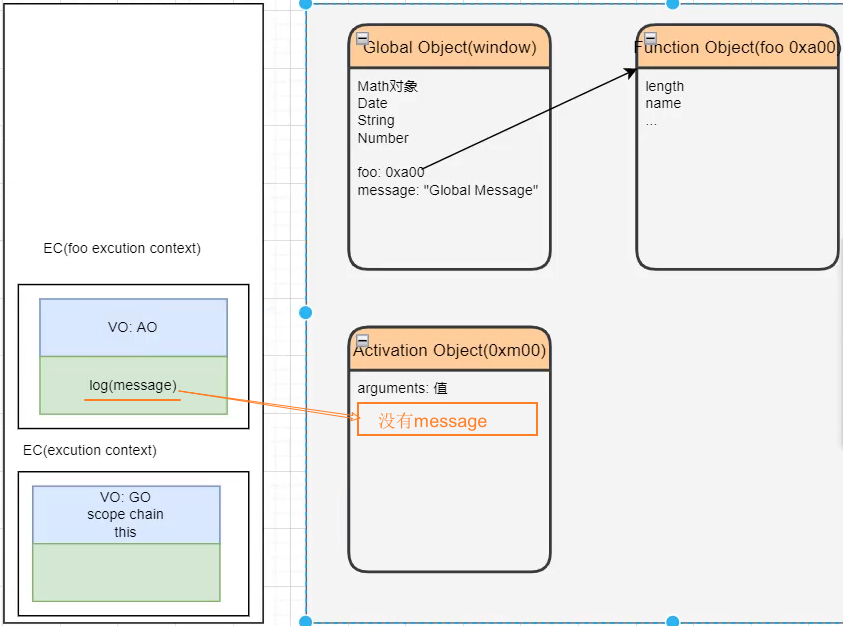
2、函数中没有自己的 message
作用域和作用域链
当进入到一个执行上下文时,执行上下文也会关联一个作用域链(Scope Chain)
作用域链是一个对象列表,用于变量标识符的求值;
当进入一个执行上下文时,这个作用域链被创建,并且根据代码类型,添加一系列的对象;
函数的作用域链和函数的定义位置有关,与调用位置无关

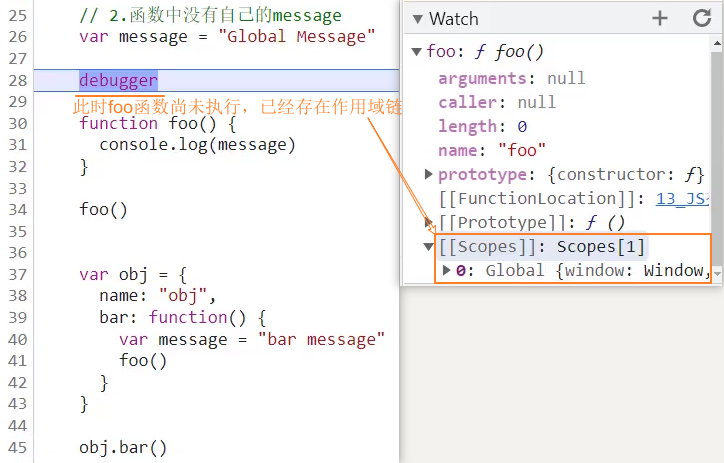
多层嵌套函数的作用域链
作用域提升面试题

JS内存管理@
JS内存管理
认识内存管理
不管什么样的编程语言,在代码的执行过程中都是需要给它分配内存的,不同的是某些编程语言需要我们自己手动的管理内存,某些编程语言会可以自动帮助我们管理内存:
内存管理的生命周期:不管以什么样的方式来管理内存,内存的管理都会有如下的生命周期:
申请:分配申请你需要的内存;
使用:使用分配的内存(存放一些东西,比如对象等);
释放:不需要使用时,对其进行释放;
不同的编程语言对于第一步和第三步会有不同的实现:
手动管理内存:比如 C、C++,包括早期的 OC,都是需要手动来管理内存的申请和释放的(malloc 和 free 函数);
自动管理内存:比如 Java、JavaScript、Python、Swift、Dart 等,它们有自动帮助我们管理内存;
对于开发者来说,JavaScript 的内存管理是自动的、无形的。
我们创建的原始值、对象、函数……这一切都会占用内存;
但是我们并不需要手动来对它们进行管理,JavaScript 引擎会帮助我们处理好它;
JS的内存管理
JavaScript 会在定义数据时为我们分配内存。
但是内存分配方式是一样的吗?
JS 对于原始数据类型内存的分配会在执行时,直接在栈空间进行分配;
JS 对于复杂数据类型内存的分配会在堆内存中开辟一块空间,并且将这块空间的指针返回值变量引用;

垃圾回收机制算法
JS的垃圾回收
垃圾回收机制(Garbage Collection, GC):是编程语言中自动管理内存的核心机制,负责识别和释放程序中不再使用的内存(即“垃圾”),从而避免内存泄漏,减轻开发者手动管理内存的负担。
因为内存的大小是有限的,所以当内存不再需要的时候,我们需要对其进行释放,以便腾出更多的内存空间。
手动管理内存的缺点:在手动管理内存的语言中,我们需要通过一些方式自己来释放不再需要的内存,比如 free 函数:
但是这种管理的方式其实非常的低效,影响我们编写逻辑的代码的效率;
并且这种方式对开发者的要求也很高,并且一不小心就会产生内存泄露(Memory Leaks)、野指针(Dangling Pointers);
所以大部分现代的编程语言都是有自己的垃圾回收机制:
垃圾回收的英文是Garbage Collection,简称GC;
对于那些不再使用的对象,我们都称之为是垃圾,它需要被回收,以释放更多的内存空间;
而我们的语言运行环境,比如 Java 的运行环境 JVM,JavaScript 的运行环境 js 引擎都会内存垃圾回收器;
垃圾回收器我们也会简称为GC,所以在很多地方你看到 GC 其实指的是垃圾回收器;
但是这里又出现了另外一个很关键的问题:GC 怎么知道哪些对象是不再使用的呢?
- 这里就要用到 GC 的实现以及对应的算法;
常见GC算法-引用计数
引用计数(Reference Counting):当一个对象有一个引用指向它时,那么这个对象的引用就+1;如果一个变量停止引用该对象,引用计数-1;当一个对象的引用为 0 时,这个对象就可以被销毁掉;
弊端:这个算法有一个很大的弊端就是会产生循环引用;
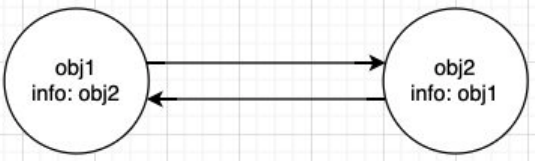
解决方案:
方案一:
obj1.info=null当
obj1=null和obj2=null时,依然会有obj1.info指向当前对象,引用计数为 1,所以无法销毁必须通过obj1.info=null才能取消引用方案二:使用WeakMap弱引用
常见GC算法-标记清除
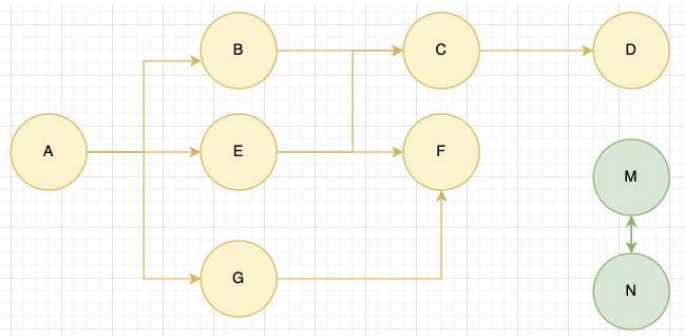
标记清除(Mark-Sweep):是垃圾回收中最经典的算法之一,通过可达性(Reachability)分析识别并回收内存中的无用对象。其核心思想是设置一个根对象(Root Object),垃圾回收器会定期从这个根开始,找所有从根开始有引用到的对象,对于那些没有引用到的对象,就认为是不可用的对象。
优缺点:
| 优势 | 劣势 |
|---|---|
✅ 解决循环引用问题(如 A→B→A) | ⚠️ 产生内存碎片(需额外整理步骤) |
| ✅ 无需维护引用计数开销 | ⚠️ 全堆扫描,执行效率较低 |
| ✅ 实现相对简单 | ⚠️ 触发时需暂停主线程(Stop-The-World) |
应用:V8 使用的是该算法
算法流程:
标记阶段(Marking)
- 步骤:
- 确定根对象(Roots):全局变量(如
window)、当前执行栈中的变量(局部变量、参数)、被引用的活动对象。 - 深度优先遍历:从根对象出发,递归遍历所有被引用的子对象,标记为“存活”。
- 确定根对象(Roots):全局变量(如
- 实现方式:
- 在对象头中添加标记位(如
marked: true/false)。 - 使用三色标记法(白→灰→黑)优化增量标记。
- 在对象头中添加标记位(如
- 步骤:
清除阶段(Sweeping)
- 步骤:
- 线性扫描整个堆内存。
- 释放所有未被标记的对象所占内存。
- 重置存活对象的标记位(为下次GC准备)。
- 内存处理:
- 简单释放:将空闲内存块加入空闲列表(Free List)。
- 合并相邻空闲块:减少内存碎片。
- 步骤:
常见GC算法-其他算法优化补充
JS 引擎比较广泛的采用的就是可达性中的标记清除算法,当然类似于 V8 引擎为了进行更好的优化,它在算法的实现细节上也会结合一些其他的算法。
标记整理(Mark-Compact): 是垃圾回收中的一种优化策略,旨在解决标记-清除算法导致的内存碎片问题。它在标记存活对象后,通过移动存活对象位置实现内存空间的连续化,从而提升内存利用率。
分代收集(Generational Garbage Collection):对象被分成两组:“新的”和“旧的”。
许多对象出现,完成它们的工作并很快死去,它们可以很快被清理;
那些长期存活的对象会变得“老旧”,而且被检查的频次也会减少;
增量收集(Incremental Collection):
如果有许多对象,并且我们试图一次遍历并标记整个对象集,则可能需要一些时间,并在执行过程中带来明显的延迟。
所以引擎试图将垃圾收集工作分成几部分来做,然后将这几部分会逐一进行处理,这样会有许多微小的延迟而不是一个大的延迟;
闲时收集(Idle-time Collection):
- 垃圾收集器只会在 CPU 空闲时尝试运行,以减少可能对代码执行的影响。
V8引擎详细的内存图
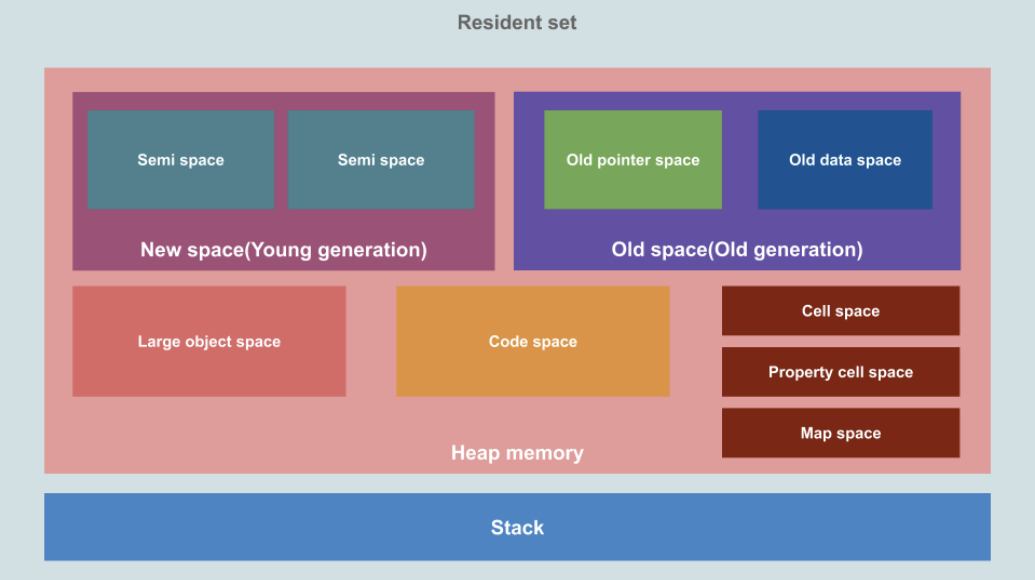
事实上,V8 引擎为了提供内存的管理效率,对内存进行非常详细的划分:
新生代空间 (New Space / Young Generation)
- 作用:主要用于存放生命周期短的小对象。这部分空间较小,但对象的创建和销毁都非常频繁。
- 组成:新生代内存被分为两个半空间:From Space 和 To Space。
- 初始时,对象被分配到 From Space 中。
- 使用复制算法(Copying Garbage Collection)进行垃圾回收。
- 当进行垃圾回收时,活动的对象(即仍然被引用的对象)被复制到 To Space 中,而非活动的对象(不再被引用的对象)被丢弃。
- 完成复制后,From Space 和 To Space 的角色互换,新的对象将分配到新的 From Space 中,原 To Space 成为新的 From Space。
老生代空间(Old Space / Old Generation)
- 作用:存放生命周期长或从新生代晋升过来的对象。
- 当对象在新生代中经历了一定数量的垃圾回收周期后(通常是一到两次),且仍然存活,它们被认为是生命周期较长的对象。
- 分为二个主要区域:
- 老指针空间(Old Pointer Space):主要存放包含指向其他对象的指针的对象。
- 老数据空间(Old Data Space):用于存放只包含原始数据(如数值、字符串)的对象,不含指向其他对象的指针。
大对象空间(Large Object Space):用于存放大对象,如超过新生代大小限制的数组或对象。
- 这些对象直接在大对象空间中分配,避免在新生代和老生代之间的复制操作。
代码空间(Code Space):存放编译后的函数代码。
单元空间(Cell Space):用于存放小的数据结构,比如闭包的变量环境。
属性单元空间(Property Cell Space):存放对象的属性值。
- 主要针对全局变量或者属性值,对于访问频繁的全局变量或者属性值来说,V8在这里存储是为了提高它的访问效率。
映射空间(Map Space):存放对象的映射(即对象的类型信息,描述对象的结构)。
- 当你定义一个 Person 构造函数时,可以通过它创建出来person1和person2。
- 这些实例(person1 和 person2)本身存储在堆内存的相应空间中,具体是新生代还是老生代取决于它们的生命周期和大小。
- 每个实例都会持有一个指向其映射的指针,这个映射指明了如何访问 name 和 age 属性(目的是访问属性效果变高)。
堆内存(Heap Memory)与栈 (Stack)
- 堆内存:JavaScript 对象、字符串等数据存放的区域,按照上述分类进行管理。
- 栈:用于存放执行上下文中的变量、函数调用的返回地址(继续执行哪里的代码)等,栈有助于跟踪函数调用的顺序和局部变量。
事件循环@
概念
进程和线程
线程和进程是操作系统中的两个概念:
进程(process):计算机已经运行的程序,是操作系统管理程序的一种方式;
线程(thread):操作系统能够运行运算调度的最小单位,通常情况下它被包含在进程中;
通俗解释:听起来很抽象,这里还是给出我的解释:
进程:我们可以认为,启动一个应用程序,就会默认启动一个进程(也可能是多个进程);
线程:每一个进程中,都会启动至少一个线程用来执行程序中的代码,这个线程被称之为主线程;
所以我们也可以说进程是线程的容器;
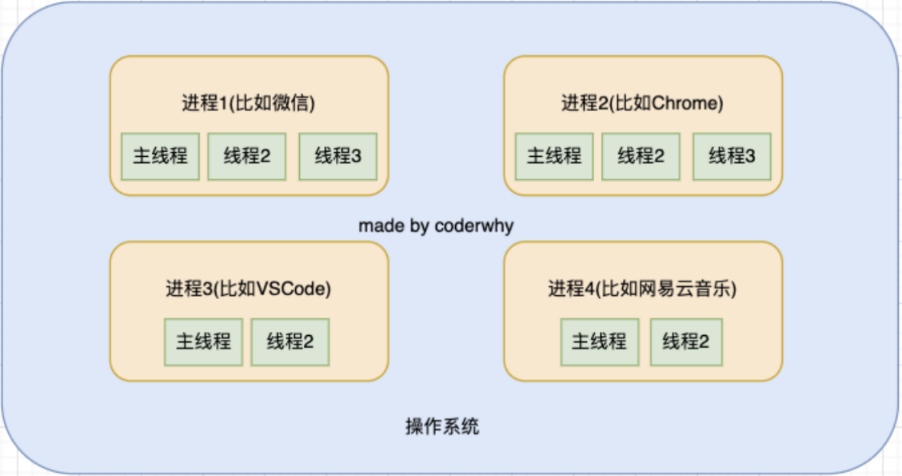
举例解释:再用一个形象的例子解释:
操作系统类似于一个大工厂;
工厂中里有很多车间,这个车间就是进程;
每个车间可能有一个以上的工人在工厂,这个工人就是线程;
图解:
操作系统的工作方式:
操作系统是如何做到同时让多个进程(边听歌、边写代码、边查阅资料)同时工作呢?
这是因为CPU的运算速度非常快,它可以快速的在多个进程之间迅速的切换;
当我们进程中的线程获取到时间片时,就可以快速执行我们编写的代码;
对于用户来说是感受不到这种快速的切换的;
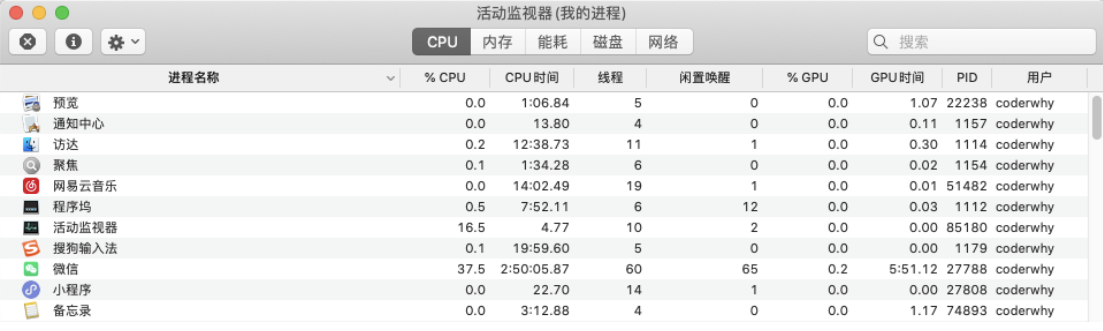
你可以在Mac的活动监视器或者Windows的资源管理器中查看到很多进程:
浏览器和JavaScript
JavaScript是单线程:
我们经常会说JavaScript是单线程(可以开启workers) 的,但是JavaScript的线程应该有自己的容器进程:浏览器或者Node。
浏览器是一个进程吗,它里面只有一个线程吗?
目前多数的浏览器其实都是多进程的,当我们打开一个tab页面时就会开启一个新的进程,这是为了防止一个页面卡死而造成所有页面无法响应,整个浏览器需要强制退出;
每个进程中又有很多的线程,其中包括执行JavaScript代码的线程;
JS代码是在一个单独的线程中执行的:
这就意味着JavaScript的代码,在同一个时刻只能做一件事;
如果这件事是非常耗时的,就意味着当前的线程就会被阻塞;
所以真正耗时的操作,实际上并不是由JavaScript线程在执行的:
浏览器的每个进程是多线程的,那么其他线程可以来完成这个耗时的操作;
比如网络请求、定时器,我们只需要在特性的时候执行应该有的回调即可;
阻塞IO和非阻塞IO
如果我们希望在程序中对一个文件进行操作,那么我们就需要打开这个文件:通过文件描述符。
- 我们思考:JavaScript 可以直接对一个文件进行操作吗?
- 看起来是可以的,但是事实上我们任何程序中的文件操作都是需要进行系统调用(操作系统封装了文件系统);
- 事实上对文件的操作,是一个操作系统的 IO 操作(输入、输出);
操作系统为我们提供了阻塞式调用和非阻塞式调用:
- 阻塞式调用: 调用结果返回之前,当前线程处于阻塞态(阻塞态 CPU 是不会分配时间片的),调用线程只有在得到调用结果之后才会继续执行。
- 非阻塞式调用: 调用执行之后,当前线程不会停止执行,只需要过一段时间来检查一下有没有结果返回即可。
所以我们开发中的很多耗时操作,都可以基于这样的 非阻塞式调用:
- 比如网络请求本身使用了 Socket 通信,而 Socket 本身提供了 select 模型,可以进行
非阻塞方式的工作; - 比如文件读写的 IO 操作,我们可以使用操作系统提供的
基于事件的回调机制;
但是非阻塞 IO 也会存在一定的问题:我们并没有获取到需要读取(我们以读取为例)的结果
- 那么就意味着为了可以知道是否读取到了完整的数据,我们需要频繁的去确定读取到的数据是否是完整的;
- 这个过程我们称之为轮训操作;
那么这个轮训的工作由谁来完成呢?
- 如果我们的主线程频繁的去进行轮训的工作,那么必然会大大降低性能;
- 并且开发中我们可能不只是一个文件的读写,可能是多个文件;
- 而且可能是多个功能:网络的 IO、数据库的 IO、子进程调用;
libuv 提供了一个线程池(Thread Pool):
- 线程池会负责所有相关的操作,并且会通过轮训等方式等待结果;
- 当获取到结果时,就可以将对应的回调放到事件循环(某一个事件队列)中;
- 事件循环就可以负责接管后续的回调工作,告知 JavaScript 应用程序执行对应的回调函数;
Event loop in node.js
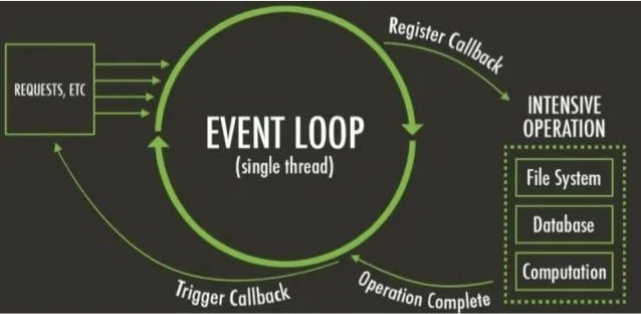
阻塞和非阻塞,同步和异步有什么区别?
阻塞和非阻塞是对于被调用者来说的;
- 在我们这里就是系统调用,操作系统为我们提供了阻塞调用和非阻塞调用;
同步和异步是对于调用者来说的;
- 在我们这里就是自己的程序;
- 如果我们在发起调用之后,不会进行其他任何的操作,只是等待结果,这个过程就称之为同步调用;
- 如果我们再发起调用之后,并不会等待结果,继续完成其他的工作,等到有回调时再去执行,这个过程就是异步调用;
宏任务
宏任务(Macro Task): 是 JavaScript 事件循环中的一种异步任务类型,用于处理需要稍后执行的代码块。它的核心特点是:在事件循环的下一轮中执行,且优先级低于微任务。
本质:代表一个独立的、完整的代码执行单元。
触发时机:在事件循环的每一轮(Tick)中,执行完当前所有微任务后,从宏任务队列中取出一个任务执行。
设计目的:处理非紧急任务(如延迟操作、I/O 回调、用户交互事件),避免阻塞主线程。
常见来源:
- JS 主代码块:初始的
<script>标签代码(本质上是第一个宏任务) - 定时器:
setTimeout、setInterval - I/O 操作:文件读写、网络请求(如
fetch的回调) - DOM 事件:
click、scroll、resize等事件回调 - UI 渲染:浏览器自动触发的渲染流程(如重绘、布局)
- 动画回调:
requestAnimationFrame(部分浏览器将其归类为宏任务)
微任务
微任务(Micro Task):是 JavaScript 事件循环中优先级最高的异步任务类型,用于处理需要立即执行的高优先级操作。它的核心特点是:在当前宏任务执行完毕后、下一个宏任务开始前,一次性清空所有微任务。
本质:代表一个需要尽快执行的轻量级任务。
触发时机:在每次宏任务执行结束后,立即清空微任务队列(包括嵌套生成的微任务)。
设计目的:处理需要即时响应的操作(如数据更新后的回调),确保在渲染前完成关键任务。
常见来源:
- Promise 回调:
Promise.then()、Promise.catch()、Promise.finally() - queueMicrotask:显式添加微任务:
queueMicrotask(() => { ... }) - MutationObserver:监听 DOM 变化的回调(如元素属性、子节点变动)
- Node.js 环境特有:
process.nextTick()(优先级甚至高于普通微任务)
关键特性:
高优先级:微任务队列的优先级高于宏任务队列,必须彻底清空后才会处理下一个宏任务。
完全清空:即使微任务中生成新的微任务(如嵌套
Promise.then),也会持续执行,直到队列为空。渲染前执行:微任务在页面渲染前执行,适合处理需要即时生效的操作(如更新 DOM 后立即读取布局属性)。
示例:
console.log("1. 主线程开始");
// 宏任务
setTimeout(() => console.log("5. 宏任务"));
// 微任务
Promise.resolve().then(() => {
console.log("3. 微任务");
// 嵌套微任务
Promise.resolve().then(() => console.log("4. 嵌套微任务"));
});
console.log("2. 主线程结束");浏览器的事件循环
浏览器的事件循环(Event Loop):是 JavaScript 在单线程环境下实现异步编程的核心机制。它通过协调 调用栈、任务队列 和 渲染管道,确保代码执行不阻塞主线程,同时高效处理用户交互、网络请求和页面渲染。
它是根据HTML5定义的规范来实现的,不同的浏览器可能会有不同的实现。
核心组成:
- 调用栈(Call Stack)
- 按顺序执行同步代码(后进先出,LIFO)。
- 当函数被调用时推入栈顶,执行完毕后弹出。
- 若栈被长时间占用(如死循环),页面会卡死(阻塞)。
- 任务队列(Task Queues)
- 宏任务队列(Macro Task Queue):存放
setTimeout、setInterval、I/O、事件回调等任务。 - 微任务队列(Micro Task Queue):存放
Promise.then、MutationObserver、queueMicrotask等高优先级任务。 - 其他队列:如
requestAnimationFrame回调队列(与渲染相关)。
- 宏任务队列(Macro Task Queue):存放
- 渲染管道(Rendering Pipeline)
- 浏览器在合适的时机执行样式计算、布局(Layout)、绘制(Paint)等操作,更新页面显示。
事件循环的作用:
- 单线程的挑战:JavaScript 只有一个主线程,所有代码依次执行,若遇到耗时操作(如网络请求),页面会卡死。
- 解决方案:事件循环将异步任务交给浏览器其他线程处理,任务完成后将回调放入队列,主线程空闲时按规则执行队列中的任务。
工作流程:
事件循环的每一次迭代称为一个 “Tick”,其执行顺序如下:
执行一个宏任务
- 从宏任务队列中取出最旧的任务(如初始的
script代码块)。 - 执行同步代码,遇到异步任务时:
- 宏任务(如
setTimeout)的回调放入宏任务队列。 - 微任务(如
Promise.then)的回调放入微任务队列。
- 宏任务(如
- 从宏任务队列中取出最旧的任务(如初始的
清空微任务队列
- 当前宏任务执行完毕后,立即依次执行微任务队列中的所有任务,直到队列为空。
- 注意:如果在处理微任务时又产生了新的微任务,会继续执行,直到彻底清空。
渲染页面(如果需要)
- 浏览器根据刷新率(通常 60Hz,约 16.6ms/帧)决定是否渲染。
- 执行与渲染相关的操作:
requestAnimationFrame回调(在渲染前执行动画逻辑)。- 浏览器进行 样式计算 → 布局(Layout)→ 绘制(Paint)。
- 若时间充裕,可能执行
requestIdleCallback(空闲时处理低优先级任务)。
取下一个宏任务
- 重复上述流程,形成循环。

关键特性:
微任务优先级高于宏任务
- 每个宏任务执行后,必须清空所有微任务才会处理下一个宏任务。
requestAnimationFrame的定位- 其回调在渲染前执行,适合处理与动画相关的逻辑,不属于宏任务或微任务。
避免阻塞主线程
- 长时间运行的同步代码(如大数据循环)会阻塞事件循环,导致页面无响应。
- 优化方案:将任务拆分为多个小任务,通过
setTimeout或queueMicrotask分批执行。
宏任务的最小延迟
setTimeout(fn, 0)的实际延迟至少为 4ms(浏览器规范限制)。
示例:
console.log("1. 主线程开始");
// 宏任务
setTimeout(() => console.log("4. 宏任务(setTimeout)"), 0);
// 微任务
Promise.resolve().then(() => console.log("3. 微任务(Promise)"));
console.log("2. 主线程结束");Node的事件循环
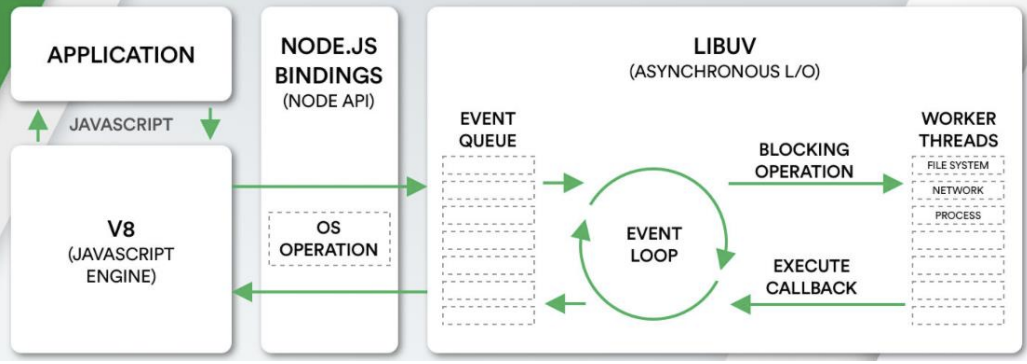
Node的事件循环(Event Loop):是其非阻塞 I/O 和异步操作的核心机制,基于 libuv 库 实现。与浏览器的事件循环不同,Node 的事件循环采用 分阶段处理模型,将不同类型的任务分配到特定阶段执行。
libuv:是一个多平台的专注于异步IO的库,最初是为Node开发的,现在也被使用到Luvit、Julia、pyuv等其他地方。
图解:
- libuv 中主要维护了一个EventLoop和worker threads(线程池);
- EventLoop 负责调用系统的一些其他操作:文件的IO、Network、child-processes等
宏任务的六个阶段:
Node事件循环会将宏任务按顺序执行以下阶段,每个阶段处理特定类型的任务:
- Timers:执行
setTimeout()和setInterval()的回调。 - Pending I/O:处理上一轮循环中延迟的 I/O 回调(如系统错误回调ECONNREFUSED)。
- Idle/Prepare:Node.js 内部使用的阶段(开发者一般无需关注)。
- Poll:检索新的 I/O 事件,执行 I/O 回调(如文件读取、网络请求),其他的宏任务基本都在此阶段执行。
- Check:执行
setImmediate()的回调。 - Close Callbacks:执行关闭事件的回调(如
socket.on('close', ...))。
执行流程:
┌───────────────────────┐
│ Timers │ ← 执行到期的定时器回调(setTimeout/setInterval)
└──────────┬────────────┘
│
┌──────────▼────────────┐
│ Pending I/O Callbacks │ ← 执行系统操作(如TCP错误)的回调
└──────────┬────────────┘
│
┌──────────▼────────────┐
│ Idle/Prepare │ ← Node.js 内部使用
└──────────┬────────────┘
│
┌──────────▼────────────┐
│ Poll │ ← 等待新I/O事件,执行I/O回调
│ │ 如果队列为空:
│ │ - 如有setImmediate,进入Check阶段
│ │ - 否则等待新事件(阻塞)
└──────────┬────────────┘
│
┌──────────▼────────────┐
│ Check │ ← 执行setImmediate回调
└──────────┬────────────┘
│
┌──────────▼────────────┐
│ Close Callbacks │ ← 执行关闭事件的回调(如socket.close)
└───────────────────────┘微任务的执行时机:
Node 的微任务分为两种,执行优先级高于宏任务:
- process.nextTick队列:在每个阶段结束后立即执行,优先级最高。
- 其他队列:如 Promise回调、queueMicrotask,它们会在
process.nextTick队列清空后执行。
示例:
setTimeout(() => console.log('3. Timeout'), 0);
setImmediate(() => console.log('4. Immediate'));
Promise.resolve().then(() => console.log('2. Promise'));
process.nextTick(() => console.log('1. NextTick'));
// 注意:如果在I/O周期内初始化,可能先执行Immediate,再执行Timeout面试题
浏览器的事件循环
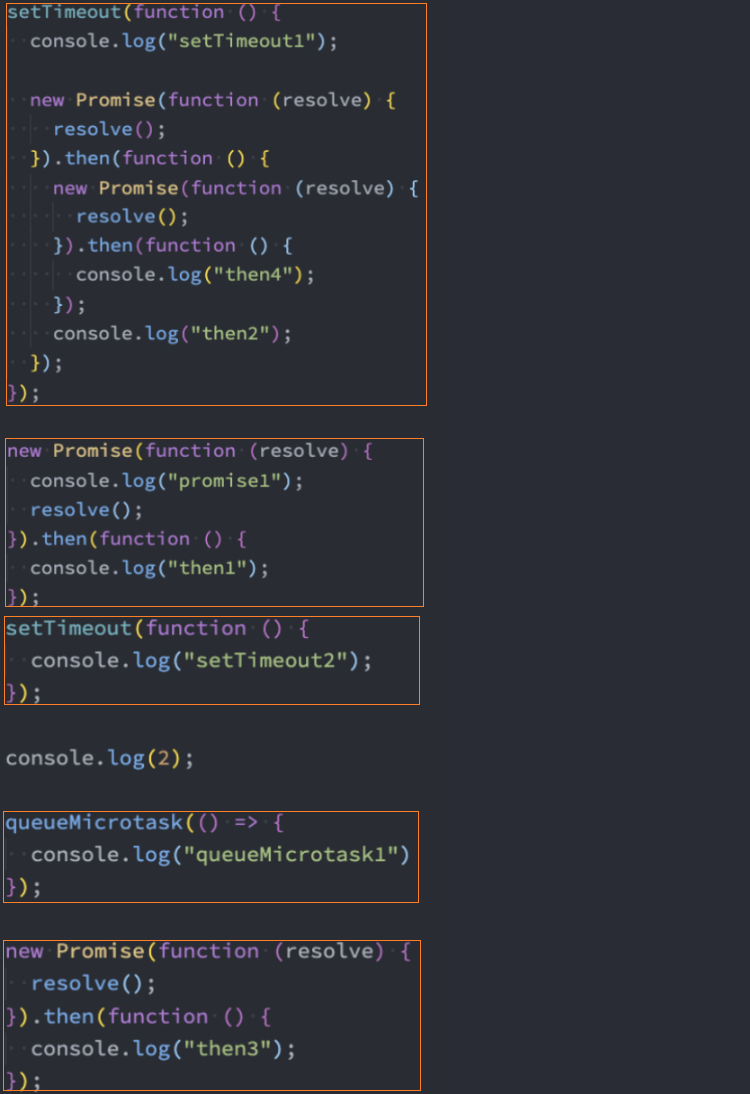
面试题1:Promise 面试题
面试题2:Promise async await 面试题

Node的事件循环
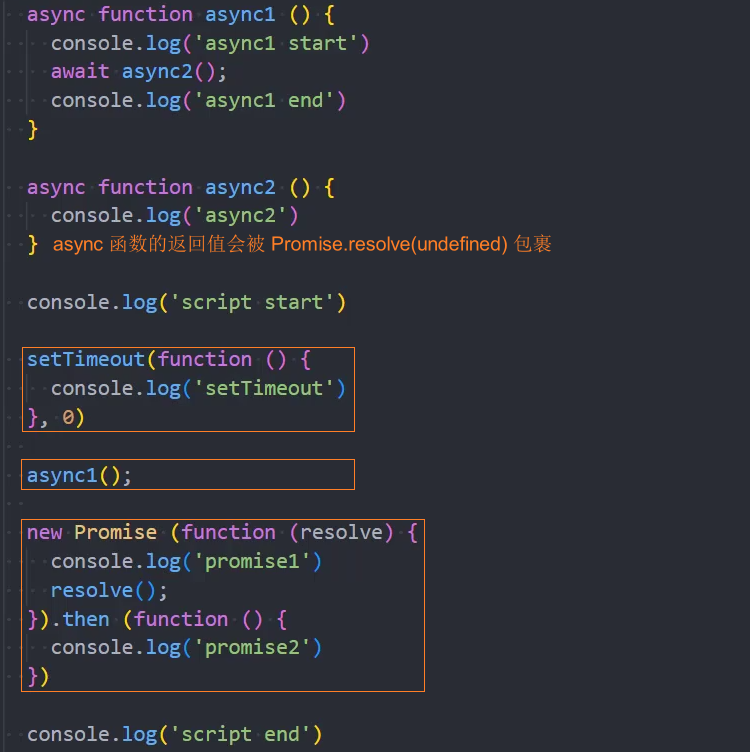
面试题1:
async function async1() {
console.log('async1 start')
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2')
}
console.log('script start')
setTimeout(function () {
console.log('setTimeout0')
}, 0)
setTimeout(function () {
console.log('setTimeout2')
}, 300)
setImmediate(() => console.log('setImmediate'))
process.nextTick(() => console.log('nextTick1'))
async1()
process.nextTick(() => console.log('nextTick2'))
new Promise(function (resolve) {
console.log('promise1')
resolve()
console.log('promise2')
}).then(function () {
console.log('promise3')
})
console.log('script end')执行结果如下:
script start
async1 start
async2
promise1
promise2
script end
nextTick
async1 end
promise3
setTimeout0
setImmediate
setTimeout2面试题2:
setTimeout(() => {
console.log('setTimeout')
}, 0)
setImmediate(() => {
console.log('setImmediate')
})执行结果:
情况一:
setTimeout
setImmediate
情况二:
setImmediate
setTimeout为什么会出现不同的情况呢?
- 在 Node 源码的 deps/uv/src/timer.c 中 141 行,有一个
uv__next_timeout的函数; - 这个函数决定了,poll 阶段要不要阻塞在这里;
- 阻塞在这里的目的是当有异步 IO 被处理时,尽可能快的让代码被执行;
int uv__next_timeout(const uv_loop_t* loop) {
const struct heap_node* heap_node;
const uv_timer_t* handle;
uint64_t diff;
// 计算距离当前时间节点最小的计时器
heap_node = heap_min(timer_heap(loop));
// 如果为空, 那么返回-1,表示为阻塞状态
if (heap_node == NULL)
return -1; /* block indefinitely */
// 如果计时器的时间小于当前loop的开始时间, 那么返回0
// 继续执行后续阶段, 并且开启下一次tick
handle = container_of(heap_node, uv_timer_t, heap_node);
if (handle->timeout <= loop->time)
return 0;
// 如果不大于loop的开始时间, 那么会返回时间差
diff = handle->timeout - loop->time;
if (diff > INT_MAX)
diff = INT_MAX;
return (int) diff;
}和上面有什么关系呢?
情况一:如果事件循环开启的时间(ms)是小于
setTimeout函数的执行时间的;- 也就意味着先开启了 event-loop,但是这个时候执行到 timer 阶段,并没有定时器的回调被放到入 timer queue 中;
- 所以没有被执行,后续开启定时器和检测到有 setImmediate 时,就会跳过 poll 阶段,向后继续执行;
- 这个时候是先检测
setImmediate,第二次的 tick 中执行了 timer 中的setTimeout;
情况二:如果事件循环开启的时间(ms)是大于
setTimeout函数的执行时间的;- 这就意味着在第一次 tick 中,已经准备好了 timer queue;
- 所以会直接按照顺序执行即可;